
 شاهین آقامعلی
شاهین آقامعلی
الگوریتم LightGBM (Light Gradient Boosting Machine) یکی از قدرتمندترین روشهای یادگیری ماشین است که توسط شرکت مایکروسافت (Microsoft) توسعه یافته است. هدف از ساخت آن، ارائهی نسخهای سریعتر، سبکتر و بهینهتر از الگوریتمهای کلاسیک Gradient Boosting است تا بتواند دادههای بسیار حجیم و پیچیده را با دقت بالا و در زمان کمتر پردازش کند. LightGBM بهطور خاص برای یادگیری روی دادههای بزرگ (Big Data) و محیطهای محاسبات توزیعشده طراحی شده و به دلیل کارایی بالا، سرعت آموزش زیاد، و مصرف حافظه کمتر، به یکی از محبوبترین الگوریتمهای یادگیری تقویتی در دنیای هوش مصنوعی و علم داده تبدیل شده است. در ادامه با آرتیجنس همراه باشید.
فلسفه طراحی LightGBM و هدف از توسعه آن
در سالهای گذشته، الگوریتمهایی مانند XGBoost نقش مهمی در افزایش دقت مدلهای پیشبینی ایفا کردند. اما با رشد حجم دادهها، نیاز به الگوریتمی احساس میشد که علاوه بر دقت، بتواند با کارایی بالا و سرعت بیشتر در محیطهای توزیعشده عمل کند. مایکروسافت با همین هدف LightGBM را توسعه داد تا از بهینهسازی سطح پایین، ساختار درختی جدید و مدیریت بهتر حافظه بهره ببرد. این الگوریتم نه تنها در مسائل طبقهبندی و رگرسیون استفاده میشود، بلکه در حوزههای پیشرفتهتری مثل پیشنهادگرها (Recommender Systems)، پیشبینی سری زمانی (Time Series Forecasting) و تحلیل ریسک مالی نیز کاربرد فراوان دارد.
نحوه کار الگوریتم LightGBM به زبان ساده
قبل از ورود به جزئیات، باید بدانیم که LightGBM بر پایهی مفهوم Boosting کار میکند. در این روش، چندین مدل ضعیف (Weak Learners) مانند درختهای تصمیم بهصورت متوالی ساخته میشوند تا با همکاری یکدیگر، یک مدل قوی ایجاد کنند.
۱. ساخت مدلهای ضعیف (Weak Learners)
در LightGBM، مدلهای پایه معمولاً درختهای تصمیم (Decision Trees) هستند. هر درخت جدید، خطاهای مدلهای قبلی را اصلاح میکند تا در نهایت مجموعهای از درختها به مدلی دقیق و پایدار منجر شوند.
۲. آموزش بر اساس گرادیان (Gradient-based Learning)
الگوریتم خطاهای پیشبینی را محاسبه کرده و با استفاده از گرادیان نزولی، پارامترهای مدل را به گونهای بهروزرسانی میکند که مجموع خطاها کاهش یابد. به همین دلیل نام آن Gradient Boosting است.
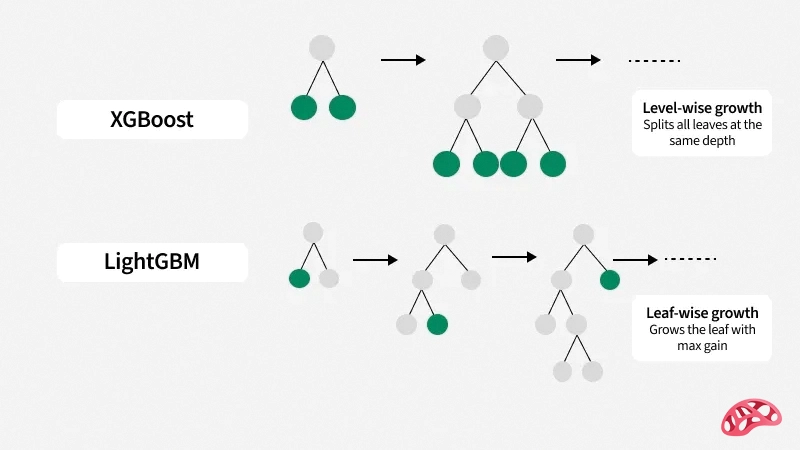
۳. استفاده از روش Leaf-wise به جای Level-wise
یکی از تفاوتهای مهمLightGBM با سایر الگوریتمهای بوستینگ این است که درختها را بهصورت leaf-wise (بر اساس برگها) رشد میدهد نه level-wise (بر اساس سطحها). در روش leaf-wise، هر بار برگی انتخاب میشود که بیشترین کاهش خطا را دارد، در نتیجه دقت نهایی بیشتر است — هرچند ممکن است مدل کمی پیچیدهتر شود.

ویژگیها و مزایای کلیدی الگوریتم LightGBM
LightGBM به دلیل طراحی خاص خود، چند مزیت چشمگیر نسبت به سایر الگوریتمهای مشابه دارد:
سرعت بالا در آموزش مدل
به لطف ساختار leaf-wise و استفاده از تکنیکهای دادهای خاص، سرعت آموزش در LightGBM بسیار بیشتر از XGBoost است. این ویژگی باعث میشود بتوان مدلهای بسیار بزرگ را در مدت کوتاهتری آموزش داد.
مصرف حافظه کمتر
LightGBM از تکنیکی به نام Histogram-based Decision Tree استفاده میکند که به جای ذخیرهی مستقیم ویژگیها، آنها را در بازههایی تقسیمبندی میکند. این روش حافظه مصرفی را به شکل چشمگیری کاهش میدهد.
مقیاسپذیری بالا (Scalability)
به لطف پشتیبانی از Parallel Learning و GPU Training، این الگوریتم میتواند روی چندین دستگاه یا گرافیک بهطور همزمان اجرا شود و در پروژههای Big Data عملکردی بینظیر ارائه دهد.
پشتیبانی از دادههای نامتوازن
در بسیاری از مسائل واقعی، دادهها متوازن نیستند (مثلاً تشخیص تقلب در تراکنشها). LightGBM با قابلیت balanced weighting این مشکل را بهخوبی مدیریت میکند.

کاربردهای الگوریتم LightGBM در دنیای واقعی
الگوریتم LightGBMیکی از پرکاربردترین و مؤثرترین الگوریتمهای یادگیری ماشین در پروژههای واقعی و صنعتی است. دلیل این محبوبیت، سرعت بالا، دقت چشمگیر و توانایی کار با دادههای حجیم است. LightGBM بهدلیل بهرهگیری از ساختار درختی و پشتیبانی از دادههای بزرگ، در طیف گستردهای از صنایع از مالی و بازاریابی گرفته تا پزشکی و تحلیل دادههای علمی به کار گرفته میشود. در ادامه با مهمترین کاربردهای این الگوریتم در دنیای واقعی آشنا میشویم.
۱. تحلیل ریسک و پیشبینی مالی
در صنعت مالی، دقت و سرعت تصمیمگیری نقش حیاتی دارد. بانکها، شرکتهای بیمه و مؤسسات اعتباری از LightGBM برای تحلیل ریسکهای مالی، شناسایی تراکنشهای غیرعادی و پیشبینی رفتار مشتریان استفاده میکنند. بهطور خاص، این الگوریتم میتواند الگوهای پنهان در دادههای مالی را شناسایی کند تا احتمال نکول وامها (Loan Default) یا تقلبهای بانکی (Fraud Detection) را کاهش دهد. از آنجا که LightGBM قادر است میلیونها رکورد تراکنش را در زمان کوتاهی پردازش کند، برای پیشبینی نوسانات بازار بورس، تحلیل سبد سرمایهگذاری (Portfolio Analysis) و مدیریت ریسک در زمان واقعی نیز گزینهای بسیار مناسب است.
۲. سیستمهای پیشنهاددهنده (Recommendation Systems)
در دنیای امروز، کاربران انتظار دارند پلتفرمها نیازشان را پیش از بیان تشخیص دهند. LightGBM در اینجا نقش کلیدی دارد. پلتفرمهای خرید آنلاین، استریم و شبکههای اجتماعی از این الگوریتم برای ساخت سیستمهای پیشنهاددهنده هوشمند استفاده میکنند. این سیستمها با تحلیل دادههای رفتاری کاربران مانند تاریخچه جستجو، کلیکها، یا سبد خرید، میتوانند محتوا یا محصولات مرتبط با علایق هر فرد را بهصورت شخصیسازیشده پیشنهاد دهند. برای مثال، فروشگاههای اینترنتی با استفاده از LightGBM میتوانند میزان احتمال خرید یک محصول توسط کاربر را پیشبینی کنند و تبلیغات هدفمندتری نمایش دهند. همچنین در پلتفرمهای محتوایی مثل YouTube یا Netflix، از LightGBM برای رتبهبندی پیشنهادات بر اساس تعاملات قبلی کاربران بهره گرفته میشود.
۳. پیشبینی سری زمانی (Time Series Forecasting)
یکی دیگر از کاربردهای مهم LightGBM، پیشبینی سری زمانی است. در این نوع تحلیل، هدف پیشبینی دادههای آینده بر اساس دادههای تاریخی است. در صنایع مختلف مانند هواشناسی، انرژی، حملونقل و بازار سرمایه، الگوریتم LightGBM میتواند روندها و الگوهای زمانی پیچیده را با دقت بالا مدلسازی کند. برای مثال، شرکتهای انرژی از آن برای پیشبینی مصرف برق در روزهای آینده استفاده میکنند تا شبکهی توزیع خود را بهینه کنند. همچنین در بازار بورس، LightGBM قادر است تغییرات قیمت سهام را با درنظرگرفتن فاکتورهای متعددی مانند حجم معاملات، اخبار اقتصادی و نوسانات تاریخی پیشبینی کند. ویژگی مهم این الگوریتم در پیشبینی سری زمانی این است که میتواند با دادههای حجیم و چندمنبعی (Multi-source Data) کار کند و حتی در شرایطی که دادهها ناقص یا نامتوازناند، عملکرد قابلاعتمادی ارائه دهد.
مقایسه LightGBM با XGBoost و CatBoost
در جدول زیر تفاوتهای مهم میان سه الگوریتم محبوب Boosting یعنی LightGBM، XGBoost و CatBoost آورده شده است:
| ویژگیها | LightGBM | XGBoost | CatBoost |
|---|---|---|---|
| شرکت توسعهدهنده | Microsoft | Open Source (DMLC) | Yandex |
| ساختار درخت | Leaf-wise | Level-wise | Symmetric Tree |
| سرعت آموزش | بسیار سریع | متوسط | سریع |
| مصرف حافظه | پایین | متوسط | پایین |
| مدیریت دادههای نامتوازن | بله | بله | بله |
| نیاز به تنظیم دستی پارامترها | زیاد | زیاد | کمتر |
| پشتیبانی از GPU | دارد | دارد | دارد |
| دقت در دادههای متنی | متوسط | خوب | عالی |
| مناسب برای Big Data | عالی | خوب | متوسط |
همانطور که جدول نشان میدهد، LightGBM از نظر سرعت، حافظه و مقیاسپذیری نسبت به سایر رقبا عملکرد بهتری دارد، اما در مقابل، CatBoost برای دادههای متنی و دستهای (Categorical Data) گزینه مناسبتری است.
تنظیمات مهم (Hyperparameters) در LightGBM
یکی از دلایل محبوبیت و کارایی بالای LightGBM، انعطافپذیری فوقالعاده آن در تنظیم پارامترهاست. این الگوریتم به کاربران اجازه میدهد تا با تنظیم دقیق مقادیر مختلف، عملکرد مدل را متناسب با نوع دادهها و هدف نهایی خود بهینه کنند. انتخاب درست این پارامترها میتواند تفاوت زیادی در دقت، سرعت و توانایی تعمیم مدل ایجاد کند. در ادامه، به معرفی و اهمیت چند پارامتر کلیدی در LightGBM میپردازیم.
1. num_leaves (تعداد برگها)
پارامتر num_leaves تعیینکنندهی حداکثر تعداد برگهای هر درخت تصمیم در LightGBMاست. هرچه این مقدار بیشتر باشد، مدل میتواند الگوهای پیچیدهتری را یاد بگیرد و دقت پیشبینی افزایش مییابد. اما باید توجه داشت که افزایش بیش از حد تعداد برگها میتواند منجر به بیشبرازش (Overfitting) شود، بهویژه در دادههای کوچک یا دارای نویز. معمولاً مقدار num_leaves باید متناسب با عمق درخت (max_depth) و حجم داده انتخاب شود تا تعادل بین دقت و تعمیم حفظ گردد.
2. learning_rate (نرخ یادگیری)
پارامتر learning_rate سرعت یادگیری مدل را کنترل میکند و مشخص میسازد که هر مرحله از آموزش تا چه اندازه بر تغییر وزنها تأثیر بگذارد. اگر مقدار آن زیاد باشد، مدل سریعتر یاد میگیرد اما ممکن است از حد بهینه عبور کند و دقت کاهش یابد. در مقابل، اگر مقدار آن خیلی کوچک باشد، آموزش طولانیتر میشود ولی مدل پایدارتری به دست میآید. معمولاً برای دستیابی به نتایج بهتر، مقدار learning_rate را کوچک (مثلاً 0.05 یا 0.1) در نظر میگیرند و تعداد تکرارها (num_iterations) را افزایش میدهند.
3. feature_fraction (درصد ویژگیها در هر تکرار)
پارامتر feature_fraction مشخص میکند که در هر تکرار آموزش، چه درصدی از ویژگیها (Features) بهصورت تصادفی برای ساخت درخت انتخاب شوند. این روش شباهت زیادی به Feature Bagging در Random Forest دارد و باعث میشود مدل از وابستگی بیش از حد به یک ویژگی خاص جلوگیری کند. در نتیجه، تعمیمپذیری مدل افزایش یافته و خطر بیشبرازش کاهش مییابد. معمولاً مقدار این پارامتر بین 0.7 تا 0.9 تنظیم میشود.
4. bagging_fraction (درصد دادهها در هر تکرار)
پارامتر bagging_fraction نقش مشابهی با feature_fraction دارد، اما بهجای ویژگیها، برای دادهها اعمال میشود. در هر مرحله از آموزش، تنها بخشی از دادهها برای ساخت درخت مورد استفاده قرار میگیرند. این کار علاوه بر کاهش احتمال بیشبرازش، سرعت آموزش مدل را نیز افزایش میدهد. برای فعال شدن این قابلیت، معمولاً باید پارامتر bagging_freq (تعداد دفعات اعمال bagging) نیز مشخص شود. مقدار رایج برای bagging_fraction معمولاً بین 0.8 تا 1.0 است.
محدودیتها و چالشهای الگوریتم LightGBM
اگرچه LightGBM یکی از سریعترین و بهینهترین الگوریتمهای تقویتی در یادگیری ماشین است، اما مانند هر مدل دیگری، چالشها و محدودیتهایی نیز دارد که در هنگام استفاده باید مدنظر قرار گیرند.
۱. حساسیت به دادههای کوچک
یکی از چالشهای اصلی LightGBM این است که در مجموعهدادههای کوچک عملکرد آن همیشه ایدهآل نیست. دلیلش این است که این الگوریتم بر پایهی ساخت درختهای تصمیم با استفاده از تکنیکهای نمونهگیری و تقسیمبندی باینری کار میکند. در دادههای کمحجم، این تقسیمبندیها ممکن است منجر به بیشبرازش (Overfitting) شوند، یعنی مدل بیش از حد به دادههای آموزشی وابسته شده و توانایی تعمیم به دادههای جدید را از دست بدهد. برای مقابله با این مشکل، معمولاً از روشهایی مانند افزودن دادههای مصنوعی (Data Augmentation)، تنظیم پارامترهای منظمسازی (Regularization Parameters) یا افزایش تعداد نمونهها استفاده میشود.
۲. نیاز به تنظیم دقیق پارامترها
کارایی واقعی LightGBM تا حد زیادی به تنظیم درست پارامترها بستگی دارد. پارامترهایی مانند num_leaves، learning_rate و max_depth اگر بهدرستی تنظیم نشوند، میتوانند به کاهش دقت یا افزایش خطا منجر شوند. بهطور خاص، پارامتر num_leaves اگر خیلی بزرگ انتخاب شود، ممکن است باعث بیشبرازش شود؛ در حالی که مقدار خیلی کوچک میتواند منجر به کمبرازش (Underfitting) گردد. بنابراین کاربران باید زمان کافی برای جستجوی شبکهای (Grid Search) یا بهینهسازی بیزین (Bayesian Optimization) اختصاص دهند تا ترکیب مناسبی از مقادیر را بیابند.
آینده الگوریتم LightGBM و نقش آن در توسعه هوش مصنوعی
الگوریتم LightGBM با ترکیب سرعت بالا، دقت زیاد و مصرف بهینهی حافظه، به یکی از پایههای اصلی در حوزهی یادگیری ماشین مدرن تبدیل شده است. با توجه به رشد تصاعدی حجم دادهها و نیاز به تحلیلهای سریعتر، آیندهی این الگوریتم بسیار روشن به نظر میرسد. در سالهای آینده انتظار میرود که LightGBM نقشی محوری در پلتفرمهای ابری (Cloud Platforms)، پردازش توزیعشده (Distributed Computing) و سیستمهای بلادرنگ (Real-Time Systems) ایفا کند. این ویژگیها به سازمانها اجازه میدهند تا مدلهای یادگیری ماشین خود را در مقیاس وسیعتر و با کارایی بیشتر اجرا کنند.
علاوه بر این، مایکروسافت و جامعهی متنباز (Open Source) به طور مداوم در حال توسعه و بهبود LightGBM هستند. پیشرفتهای آینده احتمالاً شامل بهینهسازیهای GPU، افزایش پشتیبانی از دادههای غیرساختیافته (Unstructured Data) و بهبود در تفسیرپذیری مدل (Model Interpretability) خواهد بود. این تغییرات باعث میشوند LightGBM نهتنها در کاربردهای سنتی مانند طبقهبندی و رگرسیون، بلکه در حوزههایی مانند تحلیل بلادرنگ دادههای IoT، تشخیص ناهنجاریها و پیشبینی تقاضا در سیستمهای هوشمند نیز بهصورت گستردهتری مورد استفاده قرار گیرد.
در نهایت، با رشد فناوریهای هوش مصنوعی و نیاز به مدلهای سبک و قابل استقرار در دستگاههای لبه (Edge Devices)، الگوریتم LightGBM میتواند به یکی از ابزارهای کلیدی برای پیادهسازی مدلهای هوشمند در محیطهای محدود از نظر منابع تبدیل شود. این روند نشان میدهد که آیندهی LightGBM نهتنها در مقیاس کلان دادهها، بلکه در لایههای پایینتر فناوری نیز بسیار پررنگ خواهد بود.
نتیجه گیری:
الگوریتم LightGBMیکی از بهترین پیادهسازیهای گرادیان بوستینگ است که توانسته میان دقت بالا، سرعت چشمگیر و مصرف منابع پایین تعادل ایجاد کند. این الگوریتم امروزه در قلب بسیاری از سیستمهای هوشمند از موتورهای پیشنهاددهنده تا تحلیل مالی و پیشبینیهای علمی قرار دارد. اگر به دنبال مدلی هستید که هم سریع باشد و هم دقت بالا داشته باشد، LightGBM یکی از بهترین گزینهها برای پروژههای یادگیری ماشین است.
منبع مقاله:



پاسخ :