 شاهین آقامعلی
شاهین آقامعلی
الگوریتمهای یادگیری ماشین به طور گستردهای در حوزههای مختلفی مانند تشخیص تصاویر، پردازش زبان طبیعی، و تحلیل دادههای کلان در هوش مصنوعی استفاده میشوند. یکی از الگوریتمهای مهم و مؤثر در دستهبندی و تحلیل دادههای پیچیده، ماشین بردار پشتیبان یا SVM است. SVM به دلیل توانایی بالا در یافتن مرزهای تصمیمگیری بهینه میان کلاسهای مختلف داده و کاربردهای گسترده آن، به یکی از پرکاربردترین الگوریتمهای یادگیری ماشین تبدیل شده است. در این مقاله به بررسی جزئیات و نحوه عملکرد این الگوریتم خواهیم پرداخت. در ادامه با آرتیجنسهمراه باشید.
مقدمهای بر ماشین بردار پشتیبان
ماشین بردار پشتیبان (Support Vector Machine) یک الگوریتم یادگیری نظارتشده است که عمدتاً برای دستهبندی و رگرسیون استفاده میشود. هدف اصلی SVM یافتن یک مرز تصمیمگیری یا ابرصفحه (Hyperplane) بهینه است که دادهها را به درستی به دو دسته تقسیم کند. این ابرصفحه باید به گونهای انتخاب شود که فاصله آن از نزدیکترین نقاط داده به مرز، که به بردارهای پشتیبان (Support Vectors) معروف هستند، بیشینه شود. این مفهوم از حداکثرسازی حاشیه (Margin) به دست میآید، که تفاوت اساسی SVM با بسیاری از دیگر الگوریتمهای یادگیری ماشین است.
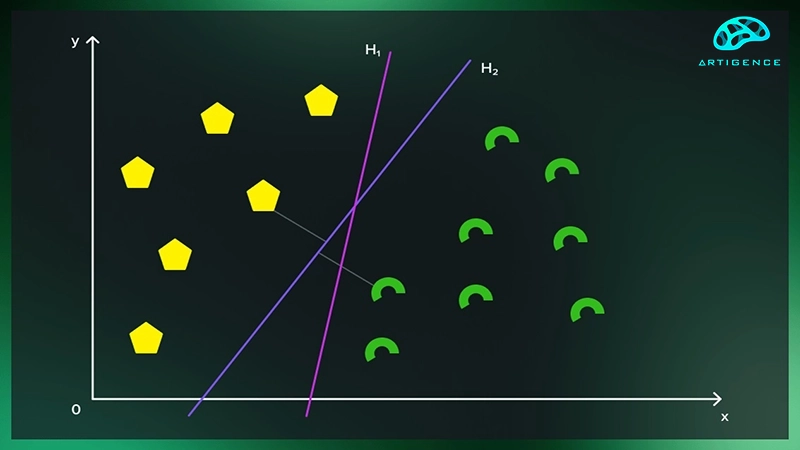
مفهوم ابرصفحه و حاشیه
یکی از اصول مهم SVM، ابرصفحه است که دادهها را به دو دسته جداگانه تقسیم میکند. این ابرصفحه میتواند یک خط در فضای دو بعدی یا یک سطح در فضاهای چند بعدی باشد. در واقع، در الگوریتم SVM، ابرصفحهای که بیشترین فاصله از نزدیکترین نقاط داده دارد به عنوان مرز تصمیمگیری انتخاب میشود. این فاصله، حاشیه نامیده میشود و هدف SVM این است که حاشیه را حداکثر کند تا دستهبندی دقیقتری داشته باشد. فرض کنید یک مجموعه داده دوبعدی داریم که شامل دو کلاس است. هر نقطه در این دادهها یک ویژگی دارد که آن را در فضای دوبعدی تعریف میکند. در این حالت، SVM سعی میکند خطی را پیدا کند که این دو کلاس را از هم جدا کند. بهترین خط آن است که از نزدیکترین نقاط هر دو کلاس بیشترین فاصله را داشته باشد. در اینجا لازم به ذکر است که یکی از مسائل مهم در استفاده از الگوریتم ها در هوش مصنوعی آشنایی با بهترین الگوریتمهای جستجو و بهینه سازی در هوش مصنوعی است.
بردارهای پشتیبان
در تعیین ابرصفحه، همه نقاط داده نقشی یکسان ایفا نمیکنند. تنها برخی از نقاط که به ابرصفحه نزدیکتر هستند و بر موقعیت آن تأثیر دارند، اهمیت دارند. این نقاط بردارهای پشتیبان نامیده میشوند. SVM تنها از این نقاط برای تعیین ابرصفحه بهینه استفاده میکند و دیگر نقاط داده در فاصله دورتری از مرز قرار دارند و تأثیری بر آن ندارند. بنابراین، بردارهای پشتیبان به SVM کمک میکنند تا تصمیمگیری دقیقتری داشته باشد و خطای مدل کاهش یابد.
انواع ماشین بردار پشتیبان
ماشین بردار پشتیبان به دو نوع اصلی تقسیم میشود: SVM خطی و SVM غیرخطی.
1. ماشین بردار پشتیبان خطی
در مواردی که دادهها به صورت خطی قابل تفکیک هستند، یعنی یک خط (یا سطح در ابعاد بالاتر) میتواند دادهها را به درستی جدا کند، از SVM خطی استفاده میشود. در این حالت، الگوریتم سعی میکند ابرصفحهای را بیابد که دادهها را به بهترین شکل از هم جدا کند.
2. ماشین بردار پشتیبان غیرخطی
در بسیاری از موارد، دادهها به صورت غیرخطی قابل تفکیک نیستند. به عنوان مثال، دادهها ممکن است به شکل دو خوشه در اطراف یک نقطه مرکزی قرار داشته باشند که با یک خط نمیتوان آنها را از هم جدا کرد. در این موارد، SVM از ترفند کرنل (Kernel Trick) استفاده میکند. این ترفند به الگوریتم امکان میدهد دادهها را به فضای چند بعدی بالاتر نگاشت کند تا بتواند یک ابرصفحه خطی در آن فضا پیدا کند که دادههای اصلی را به درستی جدا کند.
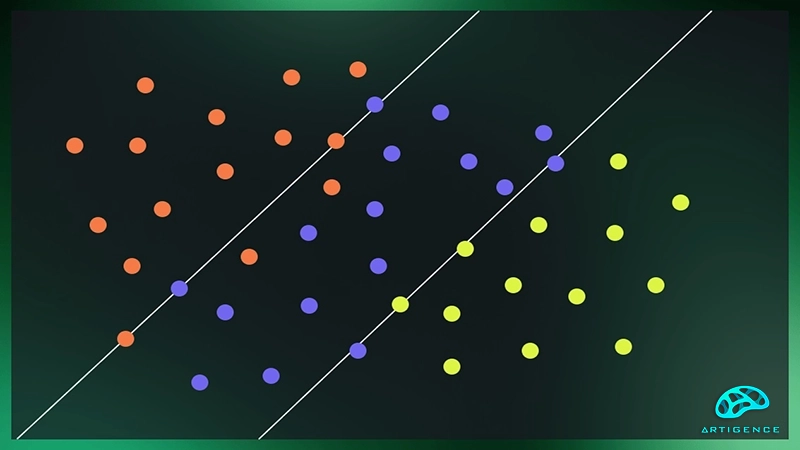
ترفند کرنل
کرنل یکی از ویژگیهای کلیدی در ماشین بردار پشتیبان است که به SVM امکان میدهد با دادههای غیرخطی نیز کار کند. کرنلها توابعی هستند که دادهها را از فضای ویژگیهای ورودی به یک فضای ویژگیهای بالاتر نگاشت میکنند. با استفاده از کرنلها، SVM میتواند ابرصفحهای را در فضای چندبعدی پیدا کند که دادههای پیچیدهتر و غیرخطی را به خوبی دستهبندی کند.
انواع کرنلهای رایج در SVM
1. کرنل خطی: زمانی که دادهها به صورت خطی قابل تفکیک هستند، از این کرنل استفاده میشود.
2. کرنل چندجملهای (Polynomial Kernel): این کرنل دادهها را به فضای چندبعدی نگاشت میکند و برای دادههای غیرخطی مناسب است.
3. کرنل تابع پایه شعاعی (RBF): یکی از کرنلهای پرکاربرد است که برای دادههایی که الگوی پیچیده دارند استفاده میشود.
4. کرنل سیگموئید: از این کرنل در شبکههای عصبی استفاده میشود و برای برخی مسائل خاص مفید است.
مزایا و معایب SVM
مانند هر الگوریتم دیگری، ماشین بردار پشتیبان نیز مزایا و معایب خاص خود را دارد. آگاهی از این نقاط قوت و ضعف میتواند به انتخاب مناسب الگوریتم در پروژههای مختلف کمک کند.
مزایا
1. دقت بالا: SVM به دلیل رویکرد مبتنی بر حداکثرسازی حاشیه، معمولاً دقت بالایی در دستهبندی دادهها دارد.
2. کار با دادههای با ابعاد بالا: SVM میتواند به خوبی با دادههایی که تعداد ویژگیهای زیادی دارند، کار کند.
3. کارآمد در مسائل غیرخطی: با استفاده از کرنلها، SVM قادر است مسائل غیرخطی را به خوبی حل کند.
4. انعطافپذیری در انتخاب کرنلها: انواع مختلفی از کرنلها وجود دارد که میتوان بر اساس نوع داده از آنها استفاده کرد.
معایب
1. زمان اجرا: در دادههای بسیار بزرگ و پیچیده، SVM ممکن است زمان زیادی برای آموزش نیاز داشته باشد.
2. انتخاب کرنل مناسب: انتخاب نادرست کرنل میتواند باعث کاهش دقت الگوریتم شود و عملکرد نامناسبی ایجاد کند.
3. حساسیت به نویز: SVM نسبت به نویز و دادههای پرت حساس است و این ممکن است بر عملکرد الگوریتم تأثیر منفی بگذارد.
کاربردهای ماشین بردار پشتیبان
ماشین بردار پشتیبان به دلیل دقت بالا و انعطافپذیری در مسائل مختلف به کار گرفته میشود. برخی از کاربردهای مهم این الگوریتم عبارتاند از:
1. تشخیص چهره: SVM در تشخیص چهره و سایر ویژگیهای تصویر کاربرد دارد.
2. تشخیص اسپم: SVM برای طبقهبندی ایمیلها به عنوان اسپم یا غیر اسپم بسیار مؤثر است.
3. پیشبینی قیمت بازار: از SVM در تحلیل دادههای مالی و پیشبینی قیمت سهام استفاده میشود.
4. پزشکی و تشخیص بیماری: در تشخیص بیماریها از طریق دادههای پزشکی، SVM به کار گرفته میشود.
نتیجهگیری
ماشین بردار پشتیبان (SVM) یک الگوریتم قوی و انعطافپذیر برای مسائل دستهبندی و رگرسیون است که به دلیل دقت بالا و توانایی کار با دادههای پیچیده و غیرخطی، به طور گستردهای در زمینههای مختلف استفاده میشود. با استفاده از کرنلهای مناسب و تنظیمات دقیق، SVM میتواند به یکی از مؤثرترین ابزارها در یادگیری ماشین تبدیل شود.
منبع مقاله: ibm




پاسخ :