 شاهین آقامعلی
شاهین آقامعلی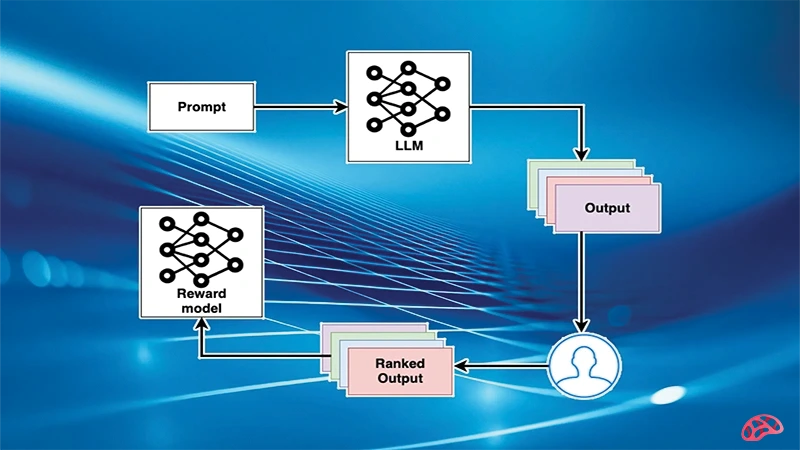
در سالهای اخیر، مدلهای زبانی بزرگ (LLMs) مانند GPT، LLaMA و Claude تحولی عظیم در حوزه هوش مصنوعی ایجاد کردهاند. با این حال، کیفیت پاسخهای این مدلها بدون استفاده از روشهای تنظیم نهایی مانند یادگیری تقویتی با بازخورد انسانی (RLHF)، ممکن است ناقص، غیرمنطقی یا نامرتبط باشد. در این مقاله، به بررسی ساختار، مزایا، چالشها و کاربردهای RLHF در ارتقای عملکرد مدلهای زبانی میپردازیم و نشان میدهیم که چگونه این روش باعث بهبود چشمگیر دقت، انسجام و قابلیت اطمینان پاسخها میشود. مدلهای زبانی بزرگ از طریق یادگیری بدون نظارت و استفاده از حجم عظیمی از دادههای متنی آموزش میبینند. با وجود توانایی بالای این مدلها در درک و تولید زبان طبیعی، در بسیاری از مواقع پاسخهایی تولید میکنند که از نظر انسانی مطلوب نیستند. برای حل این مشکل، پژوهشگران روشی موسوم به "یادگیری تقویتی با بازخورد انسانی" یا RLHF توسعه دادهاند. این روش به مدلها کمک میکند تا نه تنها از لحاظ آماری، بلکه از دیدگاه انسانی نیز پاسخهای بهتری تولید کنند. در ادامه این مقاله با آرتیجنس همراه باشید.
ساختار کلی RLHF: فرایند RLHF در سه مرحله اصلی انجام میشود:
1. پیشآموزش مدل زبانی: در این مرحله، مدل مبتنی بر پردازش زبان طبیعی با استفاده از دادههای متنی بزرگ آموزش میبیند.
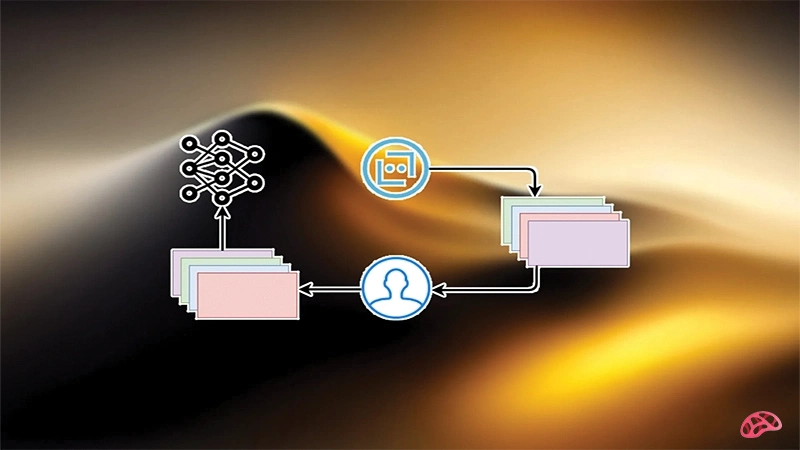
2. جمعآوری بازخورد انسانی: چندین پاسخ ممکن به یک ورودی تولید شده و ارزیابان انسانی آنها را بر اساس معیارهایی مانند دقت، انسجام، ادب و مفید بودن رتبهبندی میکنند.
3. آموزش با الگوریتم تقویتی (مانند PPO): مدل پاداش دریافت میکند یا تنبیه میشود بر اساس رتبهبندی انسانی و تلاش میکند پاسخهایی تولید کند که بیشترین پاداش را بهدست آورند.
مزایای استفاده از RLHF:
1. افزایش کیفیت پاسخها: با استفاده از بازخورد انسانی، مدل قادر است پاسخهایی نزدیکتر به انتظارات کاربران تولید کند.
2. کاهش پاسخهای مضر یا اشتباه: RLHFکمک میکند مدل از تولید محتوای توهینآمیز، نادرست یا گمراهکننده خودداری کند.
3. افزایش تعاملپذیری: پاسخها بافتمحورتر و طبیعیتر میشوند که تجربه کاربری بهتری رقم میزند.
4. تنظیم دقیقتر هدف مدل: RLHF مدل زبان بزرگ را به سمت اهداف خاص، مثلاً رفتار مودبانه یا بیطرف، هدایت میکند.
کاربردهای RLHF در مدلهای زبان:
یکی از مهمترین نمونههای استفاده از RLHF، مدل GPT-4 شرکت OpenAI است که به کمک این روش توانسته پاسخهایی منسجمتر، با دقت بالاتر و اخلاقمحورتر ارائه دهد. همچنین در مدلهای گفتوگومحور مانند ChatGPT یا Claude، RLHF باعث شده است پاسخها نهتنها دقیق، بلکه از نظر لحن و ساختار نیز انسانیتر شوند. در حوزه آموزش زبان، RLHF نقش مهمی در تطبیق سطح پاسخها با میزان درک کاربران ایفا میکند. برای مثال، در پاسخ به سوالات دانشآموزان، مدل میتواند سطح سادهتری از زبان را به کار گیرد تا یادگیری مؤثرتر شود.
ابعاد فنی :RLHF
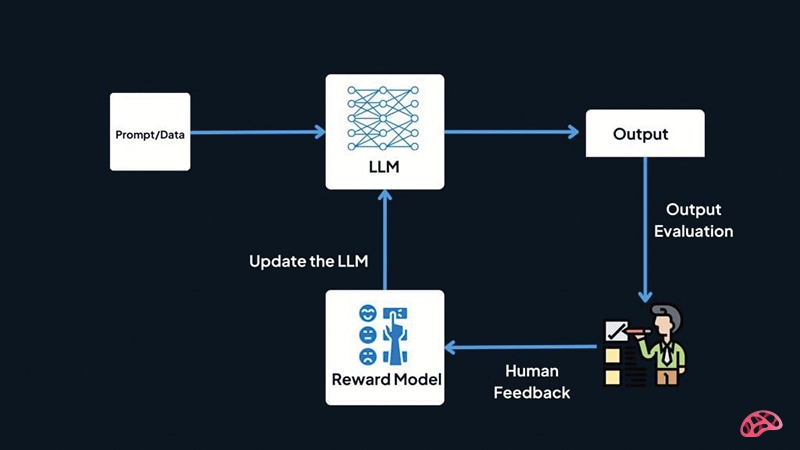
در سطح فنی، RLHF بر پایه الگوریتمهایی مانند Proximal Policy Optimization (PPO) اجرا میشود که امکان بهروزرسانی مؤثر سیاست مدل در راستای افزایش پاداش انسانی را فراهم میسازد. این الگوریتمها از مدلهای پاداش (Reward Model) بهره میگیرند که به کمک دادههای برچسبگذاریشده توسط انسان، میزان کیفیت پاسخها را ارزیابی میکنند. یکی از نوآوریهای اخیر، استفاده از معماریهای شبکه عصبی خاص برای مدل پاداش است که باعث بهبود دقت قضاوت در مورد پاسخها میشود.
چالشها و محدودیتها:
1. هزینه و زمان بالا: جمعآوری بازخورد انسانی نیازمند منابع انسانی و مالی زیادی است و گاهی برای دادههای چندزبانه یا تخصصی، بسیار دشوارتر میشود.
2. سوگیری انسانی: بازخورد انسانها میتواند ناخواسته سوگیریهایی را وارد سیستم کند که ممکن است در رفتار مدل نیز تکرار شود.
3. عدم مقیاسپذیری آسان: برای هر زبان، فرهنگ یا کاربرد خاص، نیاز به بازخورد متناسب وجود دارد که مقیاسپذیری را دشوار میسازد.
4. پیچیدگی الگوریتمی: پیادهسازی الگوریتمهای تقویتی در محیطهای زبانی با فضای پاسخ بسیار گسترده، دشوار است و نیاز به تنظیم دقیق پارامترها دارد.
تحولات و راهکارهای جدید:
برای غلبه بر چالشهای فوق، راهکارهایی در حال توسعه هستند:
• بازخورد از طریق تعامل کاربر: استفاده از رفتار واقعی کاربران در محیط واقعی بهعنوان نوعی بازخورد ضمنی.
• یادگیری تقویتی از دادههای مصنوعی: استفاده از مدلهایی که خود پاسخ تولید میکنند و از خود برای یادگیری استفاده میکنند.
• یادگیری ترکیبی: ترکیب روشهای نظارتشده با یادگیری تقویتی برای بهرهبرداری از مزایای هر دو رویکرد.
• مدلهای پاداش چندمرحلهای: استفاده از ارزیابیهای چندگانه برای یک پاسخ به منظور کاهش تأثیر سوگیری فردی.

نتیجهگیری :
یکی از مؤثرترین روشها در جهت بهبود کیفیت پاسخ مدلهای زبانی است. این رویکرد نهتنها باعث ارتقاء تجربه کاربری میشود، بلکه نقش مهمی در کاهش ریسکهای اخلاقی و عملیاتی استفاده از مدلهای هوش مصنوعی دارد. با وجود چالشها، مسیر توسعه و استفاده گسترده از این تکنیک در آینده روشن است. پژوهشهای جدید در حال حرکت به سمت کاهش وابستگی به بازخورد مستقیم انسانی، بهبود مدلهای پاداش و طراحی الگوریتمهای تقویتی کارآمدتر هستند. اگرچه هنوز محدودیتهایی وجود دارد، اما RLHFچشماندازی روشن برای توسعه مدلهای زبانی دقیق، مطمئن و انسانیتر ارائه میدهد.
منبع مقاله:



پاسخ :