
 شاهین آقامعلی
شاهین آقامعلی
الگوریتمها مجموعهای از ساختارها و دستورالعملهایی برای اجرای یک وظیفه خاص هستند. برای انجام یک کار خاص شما نیاز به یک الگوریتم دارید تا بتواند مسیر و مراحل کار شما را مشخص کنید. در هوش مصنوعی و زیر شاخههای هوش مصنوعی هم شما برای پیاده سازی یک عملکرد به الگوریتم نیاز دارید تا مسیر حرکت شما را مشخص کند. در شاخههای مختلف هوش مصنوعی مثل پردازش زبان طبیعی، یادگیری ماشین، تحلیل دادهها و تصویر برداری به شدت از الگوریتمها برای پیادهسازی عملکردهای مختلف استفاده میشود. در هوش مصنوعی الگوریتمها مختلفی وجود دارند که هر کدام در زمینههای مخصوص و مرتبط به خود مورد استفاده قرار میگیرند. یکی از این الگوریتمهای مهم، الگوریتم های خوشه بندی یا clustering میباشد. در این مقاله قصد داریم در مورد این الگوریتم بیشتر بحث کنیم و بررسی کنیم که الگوریتم های خوشه بندی چگونه و در کجا استفاده میشوند. در ادامه با آرتیجنسهمراه باشید.
الگوریتم خوشه بندی چیست؟
الگوریتم خوشه بندی یکی از پرکاربردترین الگوریتمهای حوزه هوش مصنوعی میباشد که به صورت گسترده و به منظور گروهبندی دادهها بر اساس ویژگیهای آنها به گروههای مشابه یا خوشهها، مورد استفاده قرار میگیرد. همان طور که قبلاً هم اشاره شده دادهها اهمیت بسیار زیادی در هوش مصنوعی و بخصوص پیاده سازی مدلهای یادگیری ماشین و یادگیری عمیق دارند. به عبارتی میتوان گفت که قلب یک مدل یادگیری ماشینی دادهها هستند. روش یادگیری در مدلهای یادگیری ماشین به دو روش یادگیری با ناظر و یادگیری بدون ناظر تقسیم میشود. در یادگیری بدون ناظر که دادهها بدون برچسب هستند و مدل باید از روی ویژگی دادهها آنها را دسته بندی کند، الگوریتم خوشه بندی میتواند بسیار مفید و کارآمد باشد. دسته بندی و تقسیم بندی دادههای ورودی که میتواند دارای ویژگیهای مختلفی باشند در هوش مصنوعی و مدلهای یادگیری ماشین بسیار مهم و حائز اهمیت است. بخصوص زمانی که دادهها دارای برچسب نباشند، استفاده از یک الگوریتم مناسب مثل الگوریتم خوشه بندی بسیار مهم است. الگوریتم خوشه بندی میتواند بدون توجه به برچسب دادهها و صرفاً از روی ویژگیهای آنها؛ دادههای ورودی را به دستهها یا خوشههای با ویژگیهای یکسان تقسیم کند؛ لذا میتوان نتیجه گرفت که یکی از پرکاربردترین حوزه الگوریتم خوشه بندی در مدلهای یادگیری ماشین بدون ناظر میباشد.
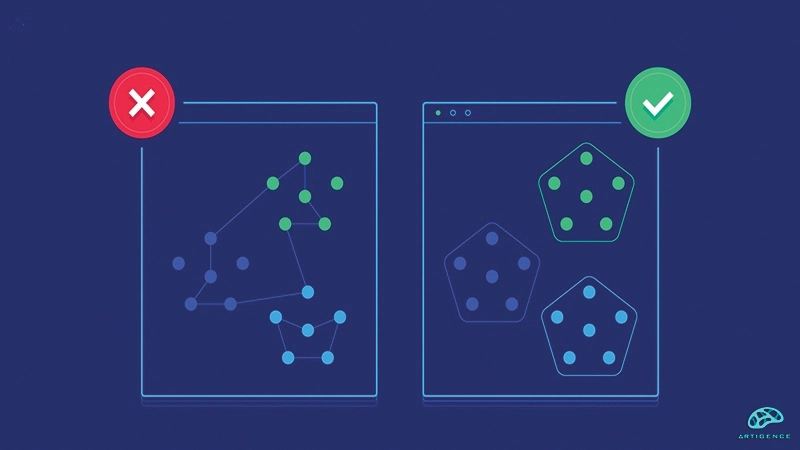
الگوریتم خوشه بندی چگونه کار میکند؟
الگوریتمهای خوشهبندی در کنار الگوریتمهای مهم هوش مصنوعی مثل الگوریتمهای شبکههای عصبی مورد استفاده قرار میگیرد و بخصوص در یادگیری بدون ناظر برای تقسیم بندی و دسته بندی دادههای ورودی به گروههای مشابه بر اساس ویژگیهای آنها بسیار کاربردی است تا بتواند از این دادههای خوشهبندیشده برای آموزش استفاده کند. عملکرد این الگوریتمها را میتوان در مراحل زیر خلاصه کرد:
انتخاب الگوریتم و تعداد خوشهها (K):
اولین مرحله از مراحل کاری الگوریتمهای خوشه بندی، انتخاب یک الگوریتم خوشه بندی مناسب و متناسب با ویژگیهای مسئله میباشد. هر کدام از الگوریتمهای خوشه بندی ویژگیهای خاص خود را دارند که متناسب با مسئله باید انتخاب شود. در بسیاری از مسائل پس از انتخاب الگوریتم مناسب خوشه بندی، لازم است تعداد خوشهها هم مشخص شود که مشخص کردن تعداد خوشهها میتواند بر اساس دانش ما از دادهها و مسئله متغیر باشد.
مقداردهی اولیه (Initialization):
در برخی از الگوریتمهای خوشه بندی مثل الگوریتم K-means ابتدا نقطهای باید به عنوان نقطه اولیه یا نقطه شروع مشخص شود تا مدل با شروع از این نقطه اولیه بتواند دادهها را خوشه بندی کند. این مرحله بعد از مرحله انتخاب الگوریتم و تعداد خوشهها انجام میشود و مرحله مقداردهی اولیه نامیده میشود.
تخصیص دادهها به خوشهها:
پس از مقدار دهی اولیه و شکل گیری خوشههای اولیه، الگوریتم بر اساس معیار و ویژگیهای دادهها آنها را به خوشههای مناسب خود تخصیص میدهد و این فرایند تا زمانی ادامه پیدا میکند که تخصیص دادهها به بهینهترین حالت خود برسد.
بهروزرسانی مراکز خوشهها:
مراکز خوشهها با توجه به میانگین دادههایی که به آن اختصاص داده شده است به روز میشوند به این معنی که با توجه به میزان تراکم و پراکندگی دادهها در اطراف مرکز خوشه، مرکز خوشه موقعیت خود را در میان دادهها به روز میکند. این مرحله به عنوان تجدید مراکز یا مرحله تکرار هم شناخته میشود.
تکرار:
مراحل 3 و 4 تا زمانی ادامه پیدا میکنند که معیاری مشخص برای اتمام مشخص شود یا مراکز به موقعیتی رسیده باشند که دیگر تغییر نکنند.
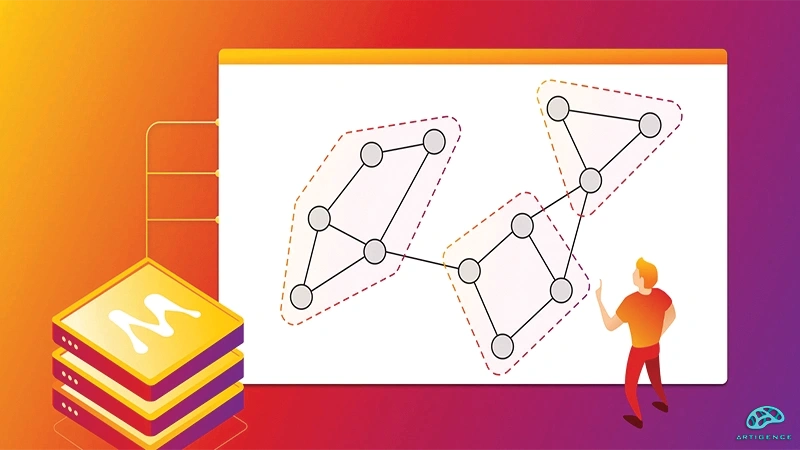
الگوریتمهای پرکاربرد خوشه بندی:
الگوریتمهای بسیاری برای خوشه بندی دادههای ورودی برای آموزش مدل وجود دارد که هر یک از این الگوریتمها مزایا و معایب خود را دارند و بسته به نوع مسئله مورد نظر انتخاب میشوند. در این قسمت از مقاله الگوریتمهای خوشه بندی به تعدادی از پرکاربردترین الگوریتمهای خوشه بندی اشاره میکنیم و در مورد هر کدام توضیحاتی ارائه میدهیم:
K-Means:
یکی از پرکاربردترین، محبوبترین و سادهترین الگوریتمهای خوشه بندی K-means نام دارد. روش کار این الگوریتم به این شکل است که ابتدا تعداد خوشهها به الگوریتم داده میشود، سپس دادههای ورودی با توجه به فاصله آنها از مرکز خوشه به هر یک از خوشهها اختصاص داده میشود
Hierarchical Clustering (خوشهبندی سلسله مراتبی):
یکی دیگر از الگوریتمهای خوشه بندی پرکاربرد، الگوریتم سلسله مراتبی میباشد که همان طور که از نامش پیداست به صورت سلسله مراتبی اقدام به خوشه بندی دادههای ورودی میکند. روش کار این الگوریتم به این شکل است که ابتدا به هر کدام از دادهها یک خوشه اختصاص داده میشود سپس با توجه به ویژگی، خوشههای مشابه با یک دیگر برای تشکیل یک خوشه بزرگتر ترکیب میشوند.
DBSCAN:
این الگوریتم یکی دیگر از انواع الگوریتمهای خوشه بندی است که دادهها را بر اساس چگالی و میزان پراکندگی آنها خوشه بندی میکند. به این صورت که خوشهها با توجه به ناحیه چگالی و فاصله کم دادهها از هم شکل میگیرد.
Agglomerative Clustering (خوشهبندی ادغامی):
این الگوریتم خوشه بندی هم یکی دیگر از الگوریتمهای خوشه بندی است که به روش سلسله مراتبی اقدام به خوشه بندی دادهها میکند. به این صورت که ابتدا هر داده به یک خوشه اختصاص داده میشود، سپس خوشهها با هم ادغام میشوند تا یک خوشه بزرگتر با دادههای هم سان را تشکیل دهند.
Fuzzy C-Means:
C-means هم یک نسخه فازی از الگوریتم خوشه بندی K-means است که اعضای دادههای ورودی را با درصدی از تعلق به هر یک از خوشهها اختصاص میدهد.
نتیجه گیری:
دادهها یکی از اصلیترین بخشها و المنتها در پیاده سازی و طراحی مدلهای هوش مصنوعی و یادگیری ماشین میباشد. شکی نیست که هر جا نیاز به استفاده و بهکارگیری دادهها باشد، تجزیه و تحلیل و دسته بندی دادهها از اهمیت بالایی برخوردار خواهد بود. الگوریتمهای خوشه بندی جز الگوریتمهایی هستند که برای تقسیم بندی و دسته بندی دادهها به صورت گسترده مورد استفاده قرار میگیرد. به بیان دیگر الگوریتمهای خوشهبندی ابزارهای قدرتمندی هستند که در تحلیل و گروهبندی دادهها کاربرد دارند. در رویکردهای یادگیری ماشین مثل یادگیری بدون ناظر که داده دارای لیبل نیستند و از قبل مشخص نیستند، این الگوریتمها میتواند برای دسته بندی دادههای ورودی با ویژگیهای مشترک بسیار مفید و کارآمد باشد. تسهیل تحلیل داده، تقویت پیشبینی و تصمیمگیری، شناخت الگوها و ارتباطات و کاهش ابهامات از جمله مزایایی هستند که استفاده از الگوریتمهای خوشه بندی به همراه خواهند داشت.




پاسخ :
Shirin
2 سال پیشدنیاییه برای خودش این هوش مصنوعی