 شاهین آقامعلی
شاهین آقامعلی
الگوریتمها نقش بسیار مهمی در حل مسائل مرتبط با هوش مصنوعی دارند. همان طور که در مقاله الگوریتم چیست اشاره شد، الگوریتمها ساختار و دستورالعملهایی هستند که در حل مسائل مختلف در زمینههای مختلف، میتوانند به ما کمک کنند. به طور کلی الگوریتمها میتوانند برای حل یک مشکل و یا مسئله خاص یک راه کار و مسیر راه ارائه دهند. هوش مصنوعی و به خصوص یادگیری ماشین یکی از حوزههایی است که از الگوریتمهای مختلف برای حل مسائل استفاده میکند که هر کدام از این الگوریتمها نام و ویژگیها و کاربردهای مختص به خود را دارند. همان طور که قبلاً اشاره شد زیر شاخه یادگیری ماشین از هوش مصنوعی و به طور کلی فرایند یادگیری در سیستمهای مبتنی بر هوش مصنوعی به سه روش عمده یادگیری با ناظر، یادگیری بدون ناظر و یادگیری تقویتی انجام میشود. هر کدام از این روشهای یادگیری برای آموزش مدل الگوریتمهای مختص به خود را دارند. الگوریتمی که میخواهیم در این مقاله آن را بررسی کنیم الگوریتم خوشه بندی K-means نام دارد. از این الگوریتم در روش یادگیری بدون ناظر برای آموزش مدل استفاده میشود و روش کاری آن به صورت مختصر همان طور که از نام آن هم پیداست خوشه بندی دادههای ورودی بر اساس ویژگیهای آنهاست. در ادامه این مقاله قصد داریم بیشتر با این الگوریتم یادگیری بودن ناظر آشنا شویم و در حد توان ویژگیها و کاربردهای آن در حوزه یادگیری ماشین را بررسی کنیم. با آرتیجنسهمراه باشید.

الگوریتم K-means چیست و چگونه کار میکند؟
در یادگیری بدون ناظر بر خلاف یادگیری نظارت شده، دادههایی که برای آموزش مدل در نظر گرفته شده است دارای لیبل یا برچسب نمیباشد تا مدل بتواند آنها را تشخیص دهد. در روش آموزش مدل به روش بدون ناظر، مدل خود باید بتوان از روی ویژگیهای موجود در دادههای ورودی برای آموزش مدل، آنها را دسته بندی و خوشه بندی کند. یکی از الگوریتم هایی که این کار را در روش آموزش بدون ناظر انجام میدهد، الگوریتم K-means است. الگوریتم K-means میتواند بدون نیاز به بررسی برچسب دادهها آنها را بر اساس ویژگیهایشان دسته بندی کند. در این الگوریتم دادههای ورودی که دارای ویژگیهای یکسان و شبیه به هم هستند در خوشههای مربوط به خود قرار میگیرند تا برای پردازشهای آتی و آموزش مدل آماده شوند. برای آشنایی بیشتر با این الگوریتم، روش کاری آن را در ادامه توضیح میدهیم. به طور کلی مراحل کار الگوریتم K-means را میتوان در سه مرحله اصلی خلاصه کرد:
مرحله مقداردهی اولیه (Initialization):
مرحله اول در الگوریتم K-means مرحله مقدار دهی و تعیین تعداد k یا همان تعداد خوشههاست که میخواهید دادهها بر اساس آنها دسته بندی شوند. پس از مشخص کردن تعداد خوشهها لازم است نقاطی به عنوان مرکز اولیه خوشهها مشخص تا موقعیت دادهها نسبت به آنها تنظیم شود. انتخاب مرکز خوشه ممکن است به صورت تصادفی یا با استفاده از روشهای دیگر صورت گیرد.
مرحله تخصیص (Assignment):
در این مرحله پس از مشخص شدن خوشهها و مراکز آنها، هر داده به نزدیکترین مرکز خوشه نسبت داده میشود. این نزدیکی معمولاً با استفاده از معیار فاصله اقلیدسی یا دیگر معیارهای فاصله سنج محاسبه میشود. این مرحله منجر به تشکیل خوشههایی میشود که دادههای هر خوشه به مرکز مربوطه نزدیکترند.
مرحله بهروزرسانی (Update):
مراکز خوشهها بر اساس میانگین دادههایی که به هر خوشه تخصیص یافتهاند، بهروزرسانی میشوند. این مرحله به اصطلاح "بهروزرسانی مراکز" نامیده میشود و باعث انتقال مراکز خوشه به نقاطی است که دادههای موجود در خوشه به میانگین نزدیکترین نقاط این خوشه هستند.
کاربرد الگوریتم K-means در هوش مصنوعی:
یکی از علل محبوبیت الگوریتم K-means وسعت دامنه کاربردهای آن است. این الگوریتم میتواند در حل بسیاری از مسائلی که با دادهها سروکار دارد به متخصصین کمک در این بخش از مقاله قصد داریم در مورد کاربردهای الگوریتم K-means در حوزه های مختلف بحث کنیم و در مورد هر کدام توضیحات کوتاهی ارائه دهیم:
بازاریابی مشتریان:
K-Means به دلیل ویژگیهای منحصر به فرد خود میتواند برای گروهبندی مشتریان بر اساس ویژگیهایی مثل سلیقهها، نیازها، یا رفتارهای خرید استفاده شود. سپس میتوان از این اطلاعات برای تصمیم گیری در زمینه بازاریابی و تبلیغات کمک استفاده کرد.
تحلیل تصویر:
یکی از حوزههایی که در آن از الگوریتم خوشه بندی K-means به شدت استفاده میشود بینایی ماشین و تشخیص الگوهای تصاویر است. الگوریتم K-Means میتواند بر اساس رنگهای مشابه موجود در تصاویر آنها را تجزیه و تحلیل و دسته بندی کند.
بانکداری و مالی:
در حوزه بانکداری میتوان از الگوریتم K-Means برای تجزیه و تحلیل رفتارهای مالی مشتریان و تجزیه و تحلیل الگوهای مالی استفاده کرد. با اطلاعات به دست آمده از تجزیه تحلیل دادههای مالی از طریق الگوریتم K-means، میتواند از این دادهها برای کاهش ریسک و تشخیص تقلب مالی استفاده کرد.
زمینه پزشکی:
پزشکی هم یکی دیگر از حوزههایی است که میتوان در آن از الگوریتم K-means برای تجزیه و تحلیل دادههای پزشکی و گروهبندی بیماران بر اساس ویژگیهای مختلف مانند نتایج آزمایشات یا سابقه بیماری استفاده کرد.
کاهش بعد دادهها:
کاهش ابعاد یکی از مسائل بسیار مهم در یادگیری ماشین و کار با تصاویر میباشد. در تعریف کوتاه کاهش ابعاد باید گفت که کاهش ابعاد شامل حذف دادههای غیر ضروری از میان دادههای ورودی است. الگوریتم K-Means به عنوان یکی از روشهای کاهش بعد میتواند مورد استفاده قرار بگیرد. این الگوریتم با تجمیع دادهها در خوشهها و استفاده از مرکز هر خوشه به عنوان نقطه نماینده، میتوان ابعاد داده را کاهش دهد.
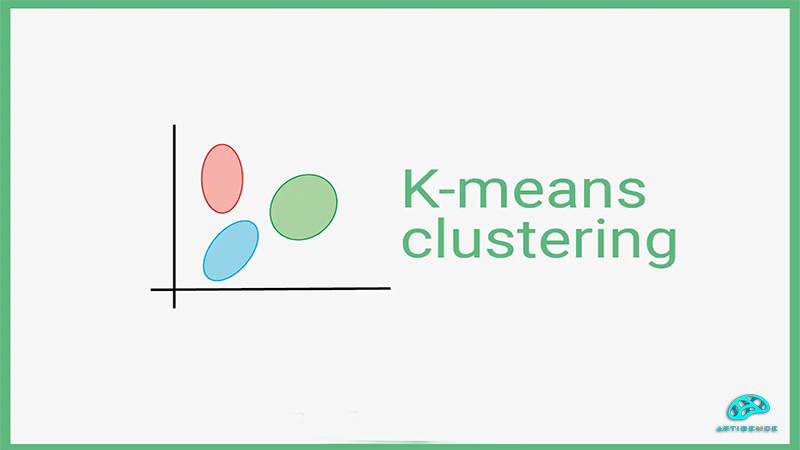
نتیجه گیری:
الگوریتم خوشه بندی K-means یکی از مهمترین الگوریتمها برای آموزش مدلها به روش بدون ناظر میباشد. در یادگیری بدون ناظر تشخیص ویژگیها و خصوصیات مختلف دادههای ورودی از اهمیت بالایی برخوردار است، چیزی که الگوریتم K-means میتوان در رسیدن به آن به ما کمک کند. با استفاده از این الگوریتم میتوان بدون نظارت بر دادهها آنها را بر اساس ویژگیهایشان دسته بندی و خوشه بندی کرد. الگوریتم K-means یک الگوریتم ساده و مؤثر است که میتواند با حجم بالایی از دادهها کار کند. همین موضوع یکی از دلایل محبوبیت این الگوریتم در میان متخصصین این حوزه است. همچنین میتوان از این الگوریتم در حوزه های مختلفی همچون پزشکی، بینایی ماشین، تجزیه و تحلیل تصاویر و بسیاری حوزه های دیگر، برای حل مسائل استفاده کرد. به طور کلی در تمام زمینههای کار با دادهها که نیاز به خوشه بندی و تقسیم بندی دادهها بر اساس ویژگیها باشد، الگوریتم K-means میتواند مورد استفاده قرار گیرد.




پاسخ :
rayan
1 سال پیشینی از این الگوریتم نمیشه در یادگیری نظارت شده استفاده کرد؟
شاهین آقامعلی
1 سال پیشیادگیری با ناظر الگوریتم های مختص به خود را دارد که بهتر است از آنها استفاه کنید مثل الگوریتم رگرسیون خطی و درخت تصمیم گیری که در ادامه در مورد این الگوریتم ها هم مقالاتی ارائه خواهد شد