 شاهین آقامعلی
شاهین آقامعلی
در دنیای امروز، دادههای عظیمی در بسیاری از حوزهها تولید میشوند و تحلیل و استفاده از این دادهها اهمیت بسیاری پیدا کرده است. یکی از چالشهای اصلی در این زمینه، خوشهبندی دادهها است، که در آن، دادههای مشابه در یک گروه قرار میگیرند. الگوریتم DBSCAN (Density-Based Spatial Clustering of Applications with Noise) یکی از قدرتمندترین الگوریتمهای خوشهبندی در یادگیری ماشین و هوش مصنوعی است که بر اساس تراکم دادهها عمل میکند. در این مقاله، به بررسی جامع این الگوریتم، مفاهیم پایه، نحوه عملکرد، کاربردها، مزایا و محدودیتهای آن میپردازیم. در ادامه با آرتیجنسهمراه باشید.
مفاهیم پایه در الگوریتم DBSCAN
الگوریتم DBSCAN بر اساس مفهوم تراکم داده طراحی شده است. بهطور کلی، این الگوریتم از سه مفهوم اصلی استفاده میکند:
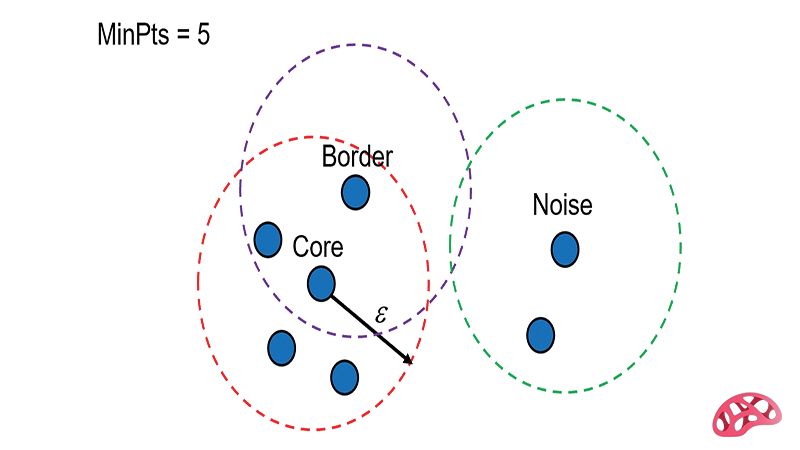
1. نقاط اصلی (Core Points): نقاطی که در شعاع مشخصی (ε) تعداد نقاط همسایه آنها بیشتر از یک مقدار آستانه (MinPts) است. این نقاط به عنوان هسته خوشهها در نظر گرفته میشوند.
2. نقاط مرزی (Border Points): نقاطی که در همسایگی نقاط اصلی قرار دارند، اما خودشان تعداد کافی از همسایگان برای تبدیل شدن به نقطه اصلی را ندارند.
3. نقاط نویزی (Noise Points): نقاطی که نه به خوشهای تعلق دارند و نه در همسایگی نقاط اصلی قرار گرفتهاند.
با استفاده از این مفاهیم، DBSCAN خوشههایی را شناسایی میکند که بر اساس تراکم دادهها تعریف شدهاند و دادههای نویزی را نادیده میگیرد.
نحوه عملکرد الگوریتم DBSCAN
الگوریتم DBSCAN که امروز اسم آن در کنار الگوریتم هایی مثل الگوریتم KNN می آید به صورت زیر عمل میکند:
1. انتخاب نقطه اولیه: الگوریتم با انتخاب یک نقطه تصادفی از مجموعه دادهها شروع میشود.
2. بررسی همسایگی: شعاع ε برای یافتن نقاطی که در نزدیکی نقطه انتخابشده قرار دارند بررسی میشود. اگر تعداد نقاط در این شعاع بیشتر از MinPts باشد، نقطه به عنوان یک نقطه اصلی شناخته میشود.
3. گسترش خوشه: اگر نقطه به عنوان یک نقطه اصلی تعیین شود، خوشهای جدید تشکیل میشود و نقاط مرتبط به آن خوشه اضافه میشوند. این فرآیند تا زمانی که تمام نقاط مرتبط شناسایی شوند ادامه پیدا میکند.
4. تشخیص نقاط نویزی: نقاطی که به هیچ خوشهای تعلق ندارند، به عنوان نویز در نظر گرفته میشوند.
5. تکرار: فرآیند برای تمام نقاط داده ادامه مییابد تا همه خوشهها و نقاط نویزی شناسایی شوند.
مزایای الگوریتم DBSCAN
الگوریتم DBSCAN مزایای متعددی دارد که آن را به یکی از محبوبترین روشهای خوشهبندی تبدیل کرده است:
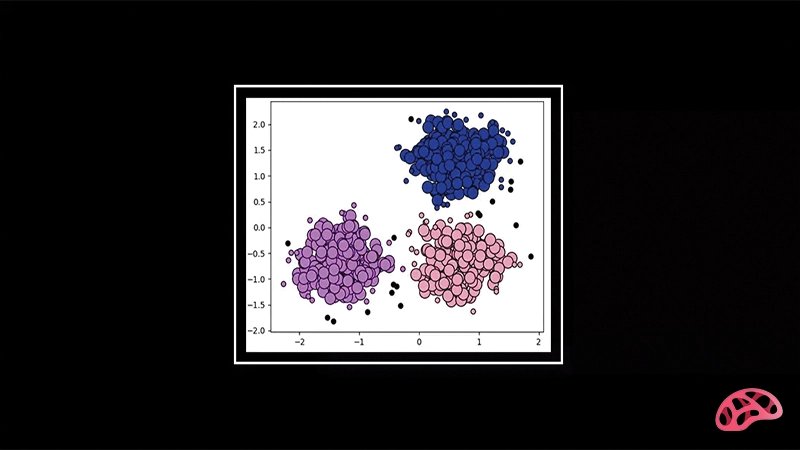
1. تشخیص خوشههای با شکل دلخواه: برخلاف الگوریتمهایی مانند K-Means که فرض میکنند خوشهها شکل کروی دارند، DBSCAN میتواند خوشههایی با اشکال پیچیده را شناسایی کند.
2. مدیریت دادههای نویزی: این الگوریتم به خوبی میتواند نقاط نویزی را تشخیص داده و از خوشهبندی حذف کند.
3. عدم نیاز به تعیین تعداد خوشهها: در DBSCAN، نیازی به تعیین تعداد خوشهها پیش از اجرا وجود ندارد. خوشهها به صورت خودکار شناسایی میشوند.
4. کاربرد در دادههای حجیم: DBSCAN برای دادههای بزرگ و پیچیده بسیار مؤثر است.
5. پایداری نسبت به مقیاس دادهها: این الگوریتم نسبت به تغییرات مقیاس دادهها حساسیت کمتری دارد، به شرطی که مقیاسبندی مناسب انجام شود.
محدودیتهای الگوریتم DBSCAN
با وجود مزایای زیاد، DBSCAN محدودیتهایی نیز دارد:
1. حساسیت به پارامترها: انتخاب مناسب پارامترهای ε و MinPts بسیار مهم است و تأثیر زیادی بر عملکرد الگوریتم دارد.
2. عملکرد ضعیف در دادههای با تراکم متفاوت: در مجموعه دادههایی که تراکم خوشهها بسیار متفاوت است، DBSCAN ممکن است عملکرد مناسبی نداشته باشد.
3. پیچیدگی محاسباتی: در دادههای بسیار بزرگ، پیچیدگی محاسباتی میتواند بالا باشد، بهویژه اگر جستجوی همسایگان بهینه نباشد.
کاربردهای DBSCAN در هوش مصنوعی
DBSCAN در بسیاری از حوزهها و کاربردهای هوش مصنوعی و یادگیری ماشین استفاده میشود:
1. تحلیل دادههای فضایی: برای شناسایی خوشهها و الگوهای فضایی در دادههایی مانند نقشهبرداری و تصاویر ماهوارهای.
2. تشخیص نقاط غیرعادی: DBSCAN میتواند برای شناسایی دادههای غیرعادی (مانند تراکنشهای مشکوک) استفاده شود.
3. پردازش تصاویر: در تقسیمبندی تصاویر و شناسایی اجزای مختلف یک تصویر.
4. تحلیل شبکههای اجتماعی: برای شناسایی گروههای مرتبط در شبکههای اجتماعی.
5. بازاریابی: در خوشهبندی مشتریان و تحلیل رفتار خرید آنها.
6. زیستشناسی: برای شناسایی خوشههای ژنها یا پروتئینها.
مقایسه DBSCAN با سایر الگوریتمها
برای درک بهتر جایگاه DBSCAN، مقایسه آن با الگوریتمهای دیگر مانند K-Means و Hierarchical Clustering مفید است:
| ویژگی | DBSCAN | K-Means | Hierarchical Clustering |
|---|---|---|---|
| شکل خوشهها | دلخواه | کروی | متغیر |
| مدیریت نویز | عالی | ضعیف | ضعیف |
| تعیین تعداد خوشهها | خودکار | نیازمند تعیین قبلی | نیازمند تعیین قبلی |
| پیچیدگی محاسباتی | بالا | پایین | بالا |
انتخاب پارامترهای مناسب برای DBSCAN
انتخاب پارامترهای ε و MinPts بسیار مهم است و میتواند با استفاده از روشهای زیر انجام شود:
1. استفاده از نمودار فاصلهها: فاصلهی k-نزدیکترین همسایهها را برای تمام نقاط داده رسم کنید و نقطهای که تغییر ناگهانی در فاصله رخ میدهد به عنوان مقدار ε انتخاب کنید.
2. انتخاب MinPts: مقدار MinPts معمولاً به تعداد ابعاد داده بستگی دارد و اغلب به صورت تجربی تعیین میشود.
نتیجهگیری
الگوریتم DBSCAN یکی از قدرتمندترین ابزارها برای خوشهبندی دادهها است که با تمرکز بر تراکم دادهها، توانایی شناسایی خوشههای پیچیده و حذف نویز را دارد. این الگوریتم در بسیاری از حوزهها کاربرد دارد و به دلیل انعطافپذیری بالا و قابلیتهای منحصربهفرد خود، همچنان به عنوان یکی از روشهای محبوب در تحلیل دادهها استفاده میشود. با این حال، برای بهرهگیری کامل از این الگوریتم، انتخاب پارامترهای مناسب و درک محدودیتهای آن بسیار اهمیت دارد.
منبع مقاله: geeksforgeeks



پاسخ :