
 شاهین آقامعلی
شاهین آقامعلی
یکی از اصلیترین بخشها در مدلهای مبتنی بر یادگیری ماشین در هوش مصنوعی، آموزش است. برای اینکه یک مدل یادگیری ماشینی بتواند یاد بگیرد و با دادههای جدید کار کند، ابتدا باید روی دادههای آموزشی، آموزش داده شود. این آموزش میتواند به روشهای مختلفی انجام شود که هرکدام مزایا و معایب خود را دارد. دادههای آموزشی ابتدا پردازش شده و نرمالیزه میشوند، سپس دادههای نرمال شده در اختیار مدل قرار میگیرد و با استفاده از الگوریتمها و تکنیکهای مختلف، مدل روی دادهها، آموزش داده میشود. اما باید در نظر داشت که پروسه آموزش مدلهای یادگیری ماشینی به این سادگی نیست و ممکن است در طول پروسه آموزش و تست مدل روی دادههای واقعی با مشکلاتی روبه رو شویم. یکی از این مشکلات که در آموزش مدلهای یادگیری ماشینی شایع است، بحث Overfitting میباشد. گاهی اوقات در آموزش مدلهای یادگیری ماشین نابهنجاریهایی به وجود میآید که ممکن است در نتیجه به دست آمده در مدل اختلال ایجاد کند. یکی از این نابهنجاریها Overfitting است که اگر بخواهیم توضیح کوتاه و خامی از آن ارائه کنیم، باید بگوییم که Overfitting به حالتی اشاره دارد که در آن مدل به شدت به دادههای آموزشی وابسته است و بیش از حد با آنها منطبق شده. مسلماً این تعریف از Overfitting بسیار ساده و ابتدایی است. لذا قصد داریم در این مقاله بیشتر در مورد این مفهوم بحث کنیم و ببینیم که Overfitting چگونه ایجاد میشود و روشهای جلوگیری از Overfitting کداماند. برای درک بهتر Overfitting در یادگیری ماشین در ادامه این مقاله با آرتیجنسهمراه باشد.
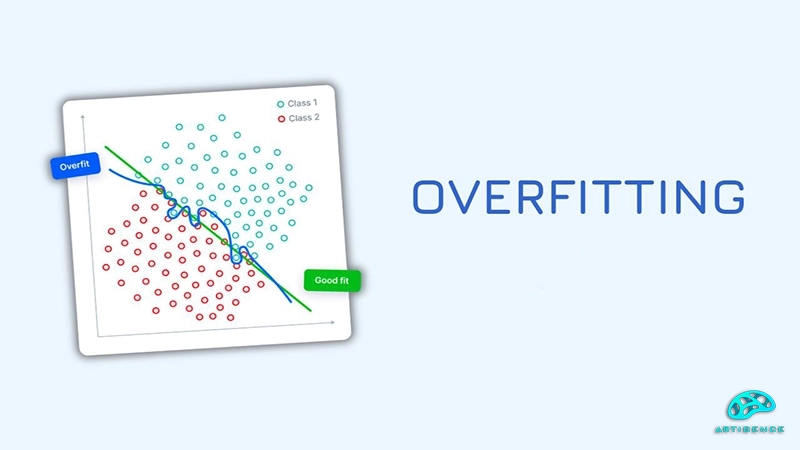
Overfitting در یادگیری ماشین چیست و چگونه ایجاد میشود؟
Overfitting در آموزش مدلهای یادگیری ماشینی، یکی از نابهنجاریها و مشکلاتی است که بر سر راه آموزش مدلها قرار دارد. Overfitting حالتی در آموزش مدلهای یادگیری ماشین است که در آن مدل بیش از حد طبیعی خود با دادههای آموزشی منطبق و به آنها وابسته میشود. بهطوریکه این وابستگی بیش از اندازه باعث ناپایداری و نقص در مواجهه با دادههای جدید میشود. شاید در اینجا این سؤال مطرح شود که تطبیق بیش از حد مدل در پروسه آموزش با دادههای آموزشی چگونه مشکل ساز میشود؟ و یا اینکه منطبق شدن بیش از بیش مدل با دادههای آموزش چه ایرادی دارد؟ برای پاسخ به این سؤالات باید گفت که اگر مدل بیش از حد طبیعی خود به دادهها وابسته شده و با آنها منطبق شود، باعث میشود که مدل در دادههای واقعی حساسیت کاذب داشته باشد و به جزئیات و نویزهای غیر ضروری حساسیت غیر طبیعی نشان دهد و این خود یعنی Overfitting. به بیان دیگر، در صورتی که مدل یادگیری ماشین بیش از حد به دادههای آموزشی وابسته باشد و اطلاعات زیادی را از دادههای آموزشی حفظ کند و به جای یادگیری الگوهای کلی و عمومی، بیش از حد به جزئیات بپردازد Overfittingاتفاق میافتد و در نتیجه دقت و عملکرد و قدرت پیش بینی مدل در برابر دادههای جدید یا دادههای تستی به شکل چشمگیری کاهش میابد.
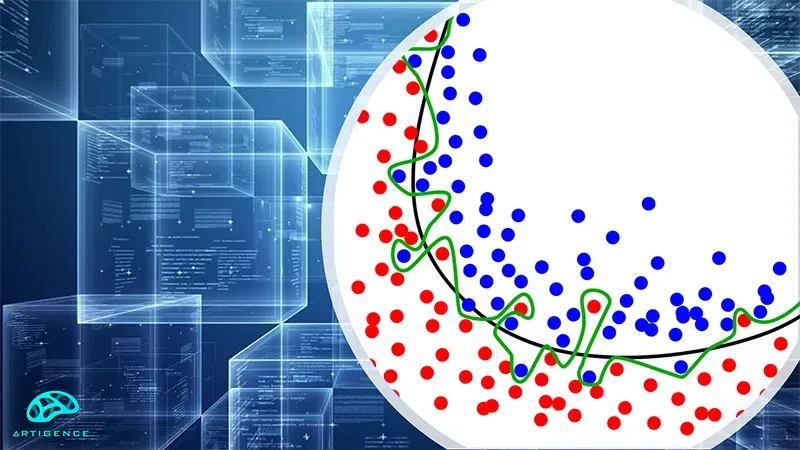
روش جلوگیری از overfitting:
حال که با مفهوم Overfitting در آموزش مدلهای یادگیری ماشین آشنا شدیم، سؤالی که مطرح میشود این است که چگونه میتوان از Overfitting در پروسه آموزش مدلهای یادگیری ماشین جلوگیری کرد. در این قسمت از مقاله، تکنیکهایی را معرفی میکنیم که با استفاده از آنها میتوان مشکل Overfitting در آموزش مدلهای یادگیری ماشین را کاهش داد.
استفاده از دادههای اعتبارسنجی (Validation Data):
یکی از روشهای جلوگیری از Overfitting استفاده از دادههای اعتبارسنجی است. دادههای اعتبارسنجی بخش از دادههای آموزشی است که از آنها جدا شده و مدل هیچ گونه مواجههای با این دادهها نداشته است. معمولاً پس از آموزش مدل با دادههای آموزشی از این بخش از دادهها برای ارزیابی مدل و اعتبارسنجی مدل استفاده میشود تا عملکرد بر روی دادههای جدید ارزیابی شود.
کاهش پیچیدگی مدل:
کاهش پیچیدگی در مدل و استفاده از مدلهای سادهتر با تعداد پارامترهای کمتر میتواند یکی دیگر از روشهایی باشد که میتواند به کاهش Overfitting کمک کند.
استفاده از تکنیکهای Regularization:
یکی دیگر از روشهای جلوگیری از Overfittingکاهش وزن و بزرگی پارامترهای آموزشی است. برای انجام این کار میتوان از تکنیکهایی مانند regularization استفاده کرد. همانطور که اشاره شد کاهش وزن و بزرگی پارامترها میتواند از Overfitting جلوگیری کند.
انتخاب مجموعه مناسبی از ویژگیها:
انتخاب درست ویژگیها یکی دیگر از موارد مهم در یادگیری ماشین و آموزش مدلهای یادگیری ماشینی است ویژگیهای معنیدار و در کنار آن کاهش ابعاد میتواند از پیچیدگی مدل و Overfitting جلوگیری کند.
استفاده از Dropout:
تکنیک dropout در شبکههای عصبی یکی دیگر از روشهایی است که میتواند با حذف بخشی از واحدهای کم اهمیت شبکههای عصبی در هر مرحله از آموزش، از تطبیق بیش از حد مدل با دادههای آموزشی جلوگیری کند.
افزایش حجم دادههای آموزشی:
حجم دادهها در آموزش هم یکی دیگر از مواردی است که میتواند در جلوگیری از Overfitting مؤثر باشد. استفاده از حجم بیشتری از دادههای آموزشی میتواند به مدل کمک کند تا الگوهای کلیتر، جامعتر و قابلتعمیمتری را یاد بگیرد و از توجه به جزئیات غیر ضروری و Overfitting جلوگیری کند.

نتیجه گیری:
امروزه یادگیری ماشین و مدلهای هوش مصنوعی مبتنی بر آن یکی از اصلیترین بخشها در توسعه هوش مصنوعی است. یکی از اصلیترین بخشها در یادگیری ماشین هم آموزش مدلهای یادگیری ماشین است. شاید در ظاهر آموزش مدلهای یادگیری ماشینی با استفاده از شبکههای عصبی و تعدادی از الگوریتمها شاید کار سادهای به نظر بیاید؛ اما وقتی در مورد موضوعی حساس شویم میتوان به مشکلات موجود در آن حوزه پی برد. با ریز شدن و حساس شدن نسبت به مدلهای مبتنی بر یادگیری ماشین و آموزش آنها هم میتوان به این نتیجه رسید که آموزش مدلهای مبتنی بر یادگیری ماشین هم مشکلات مختص به خود را دارد که یکی از آنها اتفاق افتادن Overfitting در پروسه آموزش مدل است. در مقالهای که شرح آن گذشت دیدیم که Overfitting در یادگیری ماشینو در آموزش مدل یادگیری ماشینی چگونه میتواند نتیجه به دست آمده را تحت تأثیر قرار داده و دقت مدل را کاهش دهد. همچنین در ادامه روشهایی ارائه شد که میتوان با بهکارگیری آنها از Overfitting در مدلهای یادگیری ماشینی جلوگیری کرد. در پایان لازم به ذکر است که Overfitting یکی از چالشهای اصلی بر سر راه آموزش مدلهای یادگیری ماشین است که برای عملکرد مناسب مدل باید برطرف شود.




پاسخ :