
 شاهین آقامعلی
شاهین آقامعلی
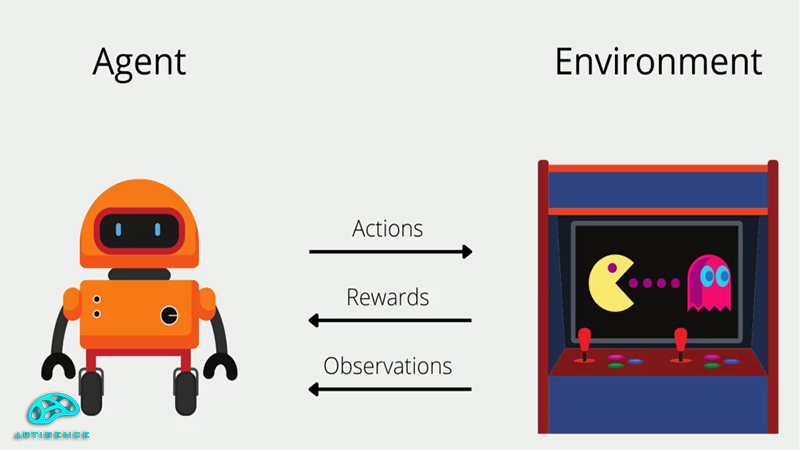
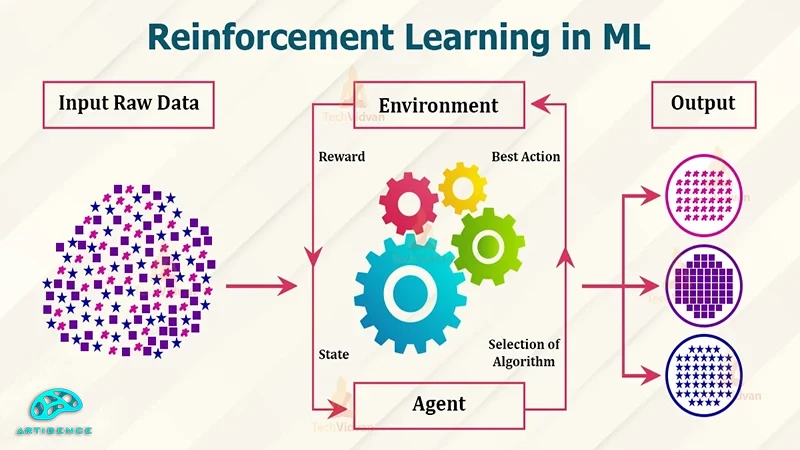
روش یادگیری تقویتی یا Reinforcement Learning یکی از روشهای یادگیری در یادگیری ماشین و هوش مصنوعی است. در کنار روشهای یادگیری مثل یادگیری با ناظر و یادگیری بدون ناظر از این روش هم در زمینههای خاصی برای پیاده سازی فرایند یادگیری استفاده میشود. در یادگیری تقویتی معمولاً از یک روش آزمون و خطا استفاده میشود که در آن عامل به ازای هر حرکت درس پاداش دریافت میکند و به مرور یاد میگیرد که تا با اتخاذ سیاست مناسب پاداش بیشتری بگیرد. برای بهینه سازی این فرایند بی شک نیاز به الگوریتمی خواهد بود که بتواند این روند را به بهترین شکل ممکن انجام دهد. الگوریتمهای مختلفی برای انجام این بهینه سازی در یادگیری تقویتی وجود دارد که الگوریتم سارسا و الگوریتم Q-Learning نمونههایی از این الگوریتمها هستند. در این مقاله قصد داریم الگوریتم Q-Learning را بررسی کنیم و ببینیم که این الگوریتم دقیقاً چیست و چگونه کار میکند. در ادامه با آرتیجنسهمراه باشید.
الگوریتم Q-Learning چیست و چگونه کار میکند؟
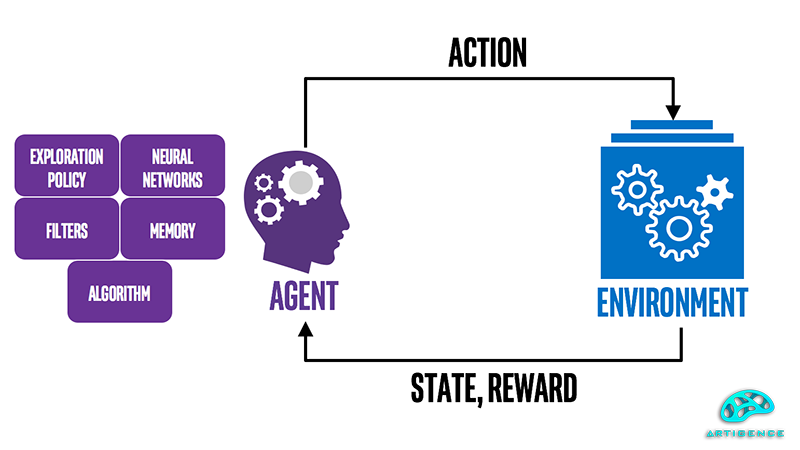
الگوریتم Q-Learning یک الگوریتم یادگیری تقویتی از نوع off-policy است. به این معنی که تابع ارزش در این الگوریتم، مستقل از سیاست و اقدام فعلی عامل به روز میشود. الگوریتم Q-Learning از مفاهیم پایهای مثل حالت، محیط، پاداش، عامل و تابع Q تشکیل میشود. با مقدار دهیهای اولیه عامل در محیط اولین عمل و حرکت خود را انجام میدهد. سپس بلافاصله محیط حالت بعدی و پاداش حرکت قبلی را به عامل میدهد. عامل نیز با دریافت این اطلاعات از محیط حرکت و اقدام بعدی خود را انجام میدهد. تابع ارزش یا Q-Value که ارزش یک جفت حالت - عمل را تخمین میزند و آن را به صورت Q(s,a) در جدول مربوط به حالتها و پاداشها ذخیره میکند. برای درک بهتر موضوع روش کار الگویتم Q-learning را با جزئیات بیشتری بررسی میکنیم:
اولین مرحله مقدار دهی اولیه میباشد. در این مرحله تمام مقادیر Q مقدار دهی اولیه میشود. سپس یک عمل a در حالت فعلی s انتخاب میشود. عمل a اجرا میشود و نتیجه که شامل حالت جدید s′ و پاداش r است، به دست میآید. پس از به دست آمدن حالت جدید و پاداش، مقدار Q برای جفت (s,a) با استفاده از فرمول زیر به دست میآید:
Q(s,a)←Q(s,a)+α(r+γa′maxQ(s′,a′)−Q(s,a))
ویژگیهای الگوریتم Q-Learning:
حالا که با الگوریتم Q-Learning و روش کار آن آشنا شدیم، در این قسمت از مقاله قسمت داریم با ویژگیهای برجسته این الگوریتم و تفاوت آن با الگوریتم های دیگر مثل الگوریتم Decision Tree بیشتر آشنا شویم. در زیر به تعدادی از این ویژگیهای اشاره کرده و در مورد هر کدام توضیحاتی ارائه میکنیم:
ساده و قابل فهم:
Q-Learning یکی از الگوریتمهایی است که به دلیل سادگی و شفافیت و سهولت در پیاده سازی بسیار مورد توجه است. این ویژگی فهم ساختار و روش کار و پیاده سازی این الگوریتم را افراد سادهتر میکند.
تضمین همگرایی:
تحت شرایط مناسب مانند استفاده از نرخ یادگیری و پارامترهای مناسب، الگوریتم Q-Learning بهینهترین مقدار Q را تضمین میکند.
یادگیری خارج خط (Off-Policy):
الگوریتم Q-Learning یکی از الگوریتمهای یادگیری تقویتی از نوع off-policy میباشد. به این معنی که سیاستی که برای انتخاب عمل استفاده میشود، میتواند با سیاستی که برای بهروزرسانی مقادیر Q استفاده میشود، متفاوت باشد. این انعطاف پذیری در به کار گیری سیاستها را هم میتوان یکی از ویژگیهای مهم این الگوریتم در نظر گرفت.
کاربردهای الگوریتم Q-Learning:
شاید در اینجا برایتان سؤال باشد که از الگوریتم Q-Learning در چه زمینههایی استفاده میشود. برای پیبردن به کاربردهای الگوریتم Q-Learning در زیر برخی از مهمترین کاربردهای آن اشاره کرده و در مورد هر کدام توضیحاتی را ارائه میکنیم:
بازیهای کامپیوتری:
شاید بازیهای رایانهای یکی از مهمترین موارد و حوزههای کاربردی الگوریتم Q-Learning باشد. الگوریتم Q-Learning میتواند برای آموزش عاملهای هوش مصنوعی در بازیهای رایانهای مورد استفاده قرار گیرد تا بهمرور زمان و طی فرایند آزمون و خطا رفتار عوامل بازی بهینه شود. بازی شطرنج و تخته نرد و یا بازی Go تعدادی دیگر از بازیهایی است که میتوان با استفاده از الگوریتم Q-Learning به عامل کمک کرد تا استراتژیهای برد و موفقیت خود را بهینه کند.
رباتیک:
آموزش رباتها جهت انجام برخی وظایف خاص مثل حرکت در یک محیط، گرفتن اشیا و یا همکاری با رباتهای دیگر، فرایندی است که میتواند از طریق آزمون و خطا و روش پاداش و جزا بهبود پیدا کند. این دقیقاً همان جایی است که میتوان از الگوریتم Q-Learning برای آموزش استفاده کرد.
اتومبیلهای خودران:
از الگوریتم Q-Learning میتوان برای آموزش سیستمهای کنترل حرکت و تصمیمگیری که در اتومبیلهای خودران مورد استفاده قرار میگیرند، استفاده کرد. این سیستمها میتوانند با کمک این الگوریتم یاد بگیرند که چگونه در جادههای پیچیده و با شرایط مختلف ترافیکی حرکت کنند.
نتیجه گیری:
همانطور که با مطالعه مقاله میتوان به آن پی برد، الگوریتم Q-Learning یکی از کاربردیترین و مهمترین الگوریتمهای یادگیری تقویتی است که به خوبی میتواند نیازهای این روش از یادگیری ماشین را برای بهینهسازیهای فرایند یادگیری انجام دهد، اما مانند هر روش و الگوریتم دیگری الگوریتم Q-Learning هم محدودیتها و چالشهای مربوط به خود را دارد، مثل نیاز به زمان و داده زیاد و عدم کارایی در صورت بزرگ بودن فضای حالت. اگر فضای حالت و عمل بزرگ باشد به موازات آن حجم جدول Q هم بالا رفته و بهروزرسانی آن سخت میشود. برای برطرف کردن محدودیتها و مشکلاتی که متوجه الگوریتم Q-Learning است، نسخه پیشرفتهتری به نام Deep Q-Learning یا DQN معرفی شده است که از شبکههای عصبی برای تقریب تابع Q استفاده میکند و میتوان از آن برای حل مسائل با فضای حالت بزرگ و پیچیده استفاده کرد. با این همه الگوریتم Q-Learning با محدودیتهایی که متوجه آن است، یکی از روشهای کلیدی در حل مسائل مرتبط با یادگیری تقویتی است.
منابع مقاله:
https://www.techtarget.com/searchenterpriseai/definition/Q-learning
https://www.simplilearn.com/tutorials/machine-learning-tutorial/what-is-q-learning
https://www.datacamp.com/tutorial/introduction-q-learning-beginner-tutorial




پاسخ :