 شاهین آقامعلی
شاهین آقامعلی
یکی از رویکردهای اصلی و پرکاربرد در حوزه هوش مصنوعی یادگیری ماشین میباشد که پیشتر در مقاله با همین عنوان توضیحات کاملی در مورد این موضوع ارائه شد. یادگیری ماشین یکی از مهمترین تکنیکها در هوش مصنوعی میباشد که میتواند به ماشین قدرت یادگیری دهد. این رویکرد با استفاده از یک سری الگوریتمها و تکنیکهای مختص به خود میتواند ویژگی یادگیری را به ماشینهای هوشمند اضافه کند. یادگیری بدون ناظر و یادگیری با ناظر جز روشهایی است که میتوان از آنها برای فرایند یادگیری در ماشینهای هوشمند استفاده کرد. یکی دیگر از روشهای یادگیری ماشینی روش یادگیری تقویتی یا Reinforcement Learning است؛ که در این مقاله موضوع بحث ماست. در تعریف خلاصه و کلی در مورد یادگیری تقویتی باید گفت که یادگیری تقویتی رویکردی است که در آن یک عامل با قرار گرفتن در یک محیط با روشهای آزمون و خطا تلاش میکند بفهمد که چه چیزهایی مفید و درست است و چه چیزهایی غیر مفید و نادرست. تعریفی که ارائه شد بسیار خام و ابتدایی بود؛ به همین خاطر در این مقاله از آرتیجنسقصد داریم که بیشتر در مورد این مفهوم بحث کنیم و سعی کنیم که تمام جوانب این روش از یادگیری ماشین را در حد توان پوشش دهیم. اگر علاقهمند به کسب اطلاعات بیشتر در این زمینه هستید، تا آخر این مقاله با ما همراه شوید.
یادگیری تقویتی چیست و چگونه کار میکند؟
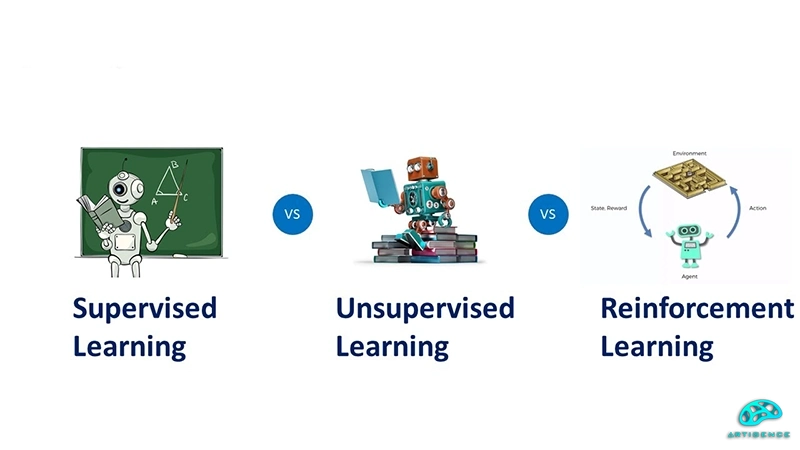
در روشهای یاد گیری نظارت شده دیدیم که ماشین از طریق دادههایی که لیبل زده شده هستند، شروع به یادگیری میکند و یا در روش یادگیری بدون نظارت ماشین قادر است حتی بدون اینکه دادههای لیبل شده باشند، ارتباط و تناسب بین آنها را تشخیص دهد. اما روش کار در روش یادگیری تقویتی کمی متفاوت است. روش کار در این رویکرد به این صورت است که با قرار دادن عامل (Agent) در محیط و با روش آزمون و خطا و جایزه و جزا سعی دارد قدرت تعامل عامل با محیط را افزایش دهد قدرت تشخیص درست و غلط را به او بیاموزد؛ به این صورت که عامل با تعامل با محیط بازخورد میگیرد، یعنی با انجام هر حرکت و یا تصمیم درست جایزه میگیرد و تشویق میشود و با هر حرکت اشتباه مقداری به عنوان خطا در نظر گرفته میشود. با این رویکرد عامل تلاش میکند که با انتخابهای درست خود پاداش بیشتری بگیرد و بیشتر بتواند با محیط اطراف خود ارتباط برقرار کند.
اجزا و عملکرد یادگیری تقویتی:
برای درک بهتر موضوع در این قسمت از مقاله یادگیری تقویتی قصد داریم بیشتر با اجزای تشکیل دهنده و نحوه عملکرد یادگیری تقویتی آشنا شویم، بررسی کنیم که این رویکرد از چه اجزایی تشکیل شده و روش کار آن چگونه است. اجزای تشکیل دهنده روش یادگیری تقویتی به شرح زیر است:
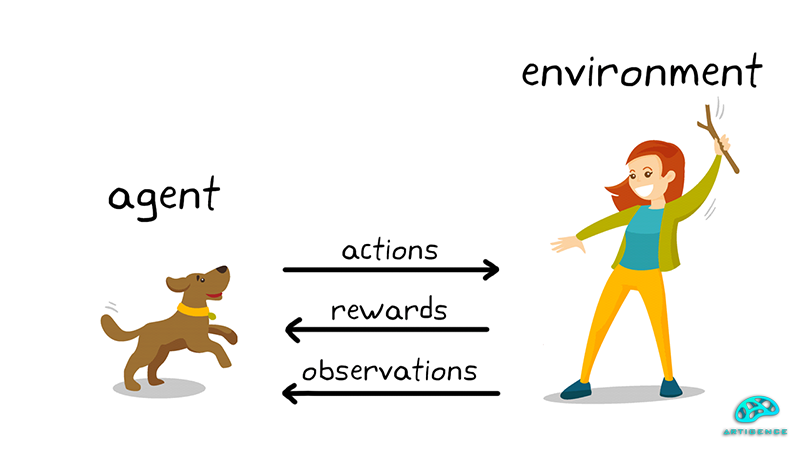
عامل (Agent): عامل در یادگیری تقویتی به موجودیتی اطلاق میشود که قرار است فرایند یادگیری روی آن اجرا شود. این عامل میتواند یک ربات، یک محیط بازی و یا حتی یک سیستم مدیریت منابع باشد.
محیط (Environment): محیط هم همانطور که از اسم آن مشخص است، بستری است که عامل در آن تعامل دارد. محیط دارای وضعیت، قوانین، اصول و شرایط و محدودیتهای خاصی است که قرار است عامل با آنها تعامل برقرار کند. یک مثال معروف برای محیط در یادگیری تقویتی میتواند محیط یک بازی کامپیوتری یا یک شبیه سازی رباتیک باشد.
وضعیت (State): وضعیت یا همان state نشان دهنده وضعیت کنونی محیط در زمانهای مشخص است. وضعیت ممکن است شامل اطلاعاتی از قبیل بردارهای ویژگی یا متغیرهای مختلف باشد که عامل برای تعامل با محیط، انتخاب و تصمیم گیری به آنها نیاز دارد.
عمل (Action): عملها شامل اقداماتی است که عامل در محیط انجام میدهد. به بیان دیگر عمل همان اقدامات از طرف عامل است که روی محیط تأثیر میگذارد.
پاداش (Reward): پاداش نیز موجودیتی است که در قبال انجام حرکت و انتخاب درست به عامل تعلق میگیرد و نمایانگر ارزش عملکرد عامل در محیط است. هدف از پاداش دادن به عامل تشویق او به دریافت پاداش بیشتر و تعامل بهینهتر با محیط است.
سیاست (Policy): سیاست نشان میدهد که عامل در هر وضعیت چه عملی را انتخاب میکند. هدف اصلی در یادگیری تقویتی این است که سیاست یا همان انتخاب عمل از طرف عامل را با دادن پاداش بهینه کند.
الگوریتمهای یادگیری تقویتی:
یادگیری تقویتی از برخی الگوریتمهای مختص به خود برای آموزش عامل استفاده میکند. هدف استفاده از این الگوریتمها این است که تجربیات عامل در محیط را برای کسب پاداش بیشتر بهینه کنند. در زیر به سه الگوریتم از الگوریتمهای مهم و پرکاربرد در الگوریتم یادگیری تقویتی برای آموزش عامل اشاره میکنیم و در مورد هر کدام توضیحاتی ارائه میدهیم.
Q-learning :Q-learning یکی از پرکاربردترین الگوریتم یادگیری تقویتی میباشد که بر اساس یک جدول مقدار Q، میزان بهینگی یک عمل در یک وضعیت را برآورد میکند. این الگوریتم فرایند یادگیری را به صورت آفلاین انجام میدهد.
SARSA :SARSA (State-Action-Reward-State-Action) یکی دیگر از الگوریتم مدل مبنایی است که همانند الگوریتم Q-learning از یک جدول Q برای تخمین ارزش و بهینگی عملها در وضعیتهای مختلف استفاده میکند. این الگوریتم در حین تعامل با محیط آموزش میبیند و برای یادگیری بهینه سیاست بسیار کاربردی است.
DQN :Deep Q-Network (DQN) هم به روش جدول مقدار Q، میزان بهینگی و ارزش عمل را تخمین میزند، فقط تنها تفاوتش با الگوریتمهای قبلی این است که DQN تخمین ارزش عمل را با کمک شبکههای عصبی عمیق انجام میدهد. این الگوریتم برای حل مسائل در ابعاد بزرگ و متنوع بسیار کارآمد است.
کاربردهای یادگیری تقویتی:
هر یک از روشها و تکنیکها در یادگیری ماشین حوزههای کاربردی مختص به خود را دارند. در این قسمت از مقاله میخواهیم حوزه کاربردی یادگیری تقویتی را در فرایند یادگیری ماشین بررسی کنیم. از یادگیری تقویتی در زمینهای مختلف و متنوعی استفاده میشود که در زیر به برخی از این زمینهها اشاره میشود و در مورد هر کدام توضیحات مختصری ارائه میشود.
رباتیک: یکی از زمینههای معروف استفاده از یادگیری تقویتی، رباتها میباشند. یکی از چالشهای بر سر راه رباتها ایجاد ارتباط بهینه و هوشمند ما محیط اطراف خود میباشد که برای رسیدن به این قابلیت، یادگیری تقویتی میتواند گزینه مناسبی باشد. امروزه انواع رباتهای مختلف از رباتهای خدماتی گرفته تا رباتهای صنعتی برای یادگیری و ایجاد ارتباط با محیط اطراف از یادگیری تقویتی استفاده میکنند.
بازیهای کامپیوتری: یکی دیگر از زمینههای محبوب که از یادگیری تقویتی در فرایند یادگیری استفاده میکند صنعت بازیهای کامپیوتری است. این صنعت برای ایجاد ارتباط هر چه بهتر کاراکترهای بازی با محیط، تنظیم سطح دشواری بازی، ایجاد رفتارهای هوش مصنوعی و بهبود تجربه بازی برای بازیکنان از یادگیری تقویتی استفاده میکند.
بهداشت و درمان: در حوزه بهداشت و درمان نیز از یادگیری تقویتی استفاده میشود. از یادگیری تقویتی میتوان برای تشخیص بیماری و روند درمان پزشکی و بهینه سازی درمان استفاده کرد.
خودروهای خودران: خودروهای خودران نیز یکی از حوزههایی است که از یادگیری تقویتی در امر فرایند یادگیری استفاده میکند. این نوع از یادگیری به خودروهای خودران این امکان را میدهد تا به منظور تصمیم گیری و کنترل در محیطهای متغیر بهترین انتخاب را داشته باشند.
نتیجه گیری:
با پیشرفت روز افزون هوش مصنوعی و به خصوص شاخه یادگیری ماشین در این حوزه توجه به فرایند یادگیری در ماشینهای هوشمند تبدیل به یک امر مهم شده است. روزبهروز روشها و تکنیکهای بهینهتر برای پیاده سازی امر یادگیری در ماشین به کار گرفته میشود. یادگیری بدون ناظر و یادگیری نظارت شده یکی از این روشها برای آموزش ماشینهای هوشمند است. ولی در کنار این رویکردها از یادگیری ماشین روش دیگری برای یادگیری ماشین وجود دارد که حوزه کاربردی آن کمی متفاوتتر از یادگیری با یا بدون ناظر است. این روش از یادگیری با نام یادگیری تقویتیشناخته میشود و برای آموزش عامل مورد نظر از روش آزمون و خطا استفاده میکند. در هر مرحله از یادگیری تقویتی با پاداش داد به عامل تلاش میشود تا عامل مورد نظر در مسیر درست باقی بماند. از این روش یادگیری میتواند در زمینهایی مثل کنترل رباتها، صنایع تولیدی و حتی امور مالی و تجاری استفاده کرد.



پاسخ :
arzsanj
2 سال پیشخیلی ممنون مقاله کامل و خوبی بود