
 شاهین آقامعلی
شاهین آقامعلی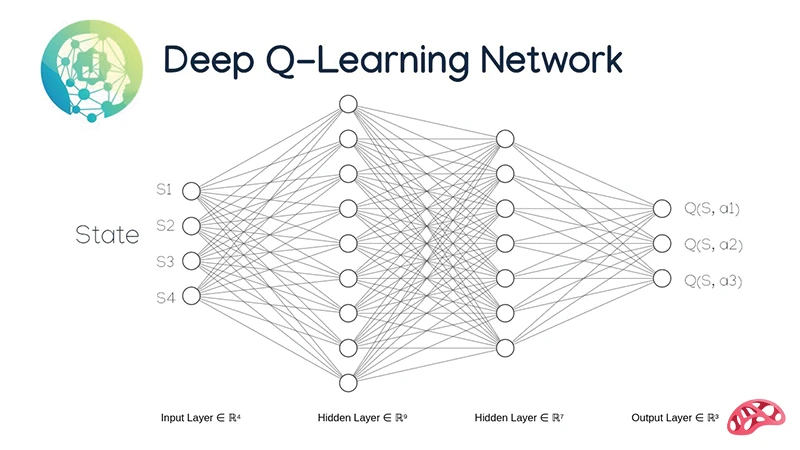
هوش مصنوعی در دهه اخیر جهشهای چشمگیری را تجربه کرده است، اما یکی از مهمترین نقاط عطف این مسیر، ظهور الگوریتم Deep Q-Network (DQN) بود. الگوریتمی که برای اولینبار توانست یادگیری تقویتی کلاسیک را با قدرت شبکههای عصبی عمیق ترکیب کند و راه را برای موفقیتهای بزرگی مانند شکست انسان در بازیهای پیچیده، کنترل رباتها و تصمیمگیری هوشمند در محیطهای پویا هموار سازد. DQN نهتنها یک الگوریتم، بلکه آغازگر نسل جدیدی از سیستمهای یادگیرنده مبتنی بر تجربه است. در ادامه با آرتیجنس همراه باشید.
Deep Q-Network (DQN) چیست؟
Deep Q-Network یا به اختصار DQN الگوریتمی در حوزه یادگیری تقویتی عمیق (Deep Reinforcement Learning) است که توسط شرکت DeepMind در سال ۲۰۱۳ معرفی شد. این الگوریتم ترکیبی از Q-Learning و شبکههای عصبی عمیق است و هدف آن یادگیری یک سیاست بهینه برای تصمیمگیری در محیطهایی با فضای حالت بسیار بزرگ یا پیوسته است.
در یادگیری تقویتی، عامل (Agent) با محیط تعامل میکند، اقدام (Action) انجام میدهد، پاداش (Reward) دریافت میکند و تلاش میکند مجموع پاداشهای آینده را بیشینه کند. مشکل اصلی Q-Learning کلاسیک این بود که برای محیطهای بزرگ، ذخیره و بهروزرسانی جدول Q عملاً غیرممکن میشد. DQN این مشکل را با جایگزینی جدول Q با یک شبکه عصبی حل کرد.
چرا DQN اهمیت تاریخی دارد؟
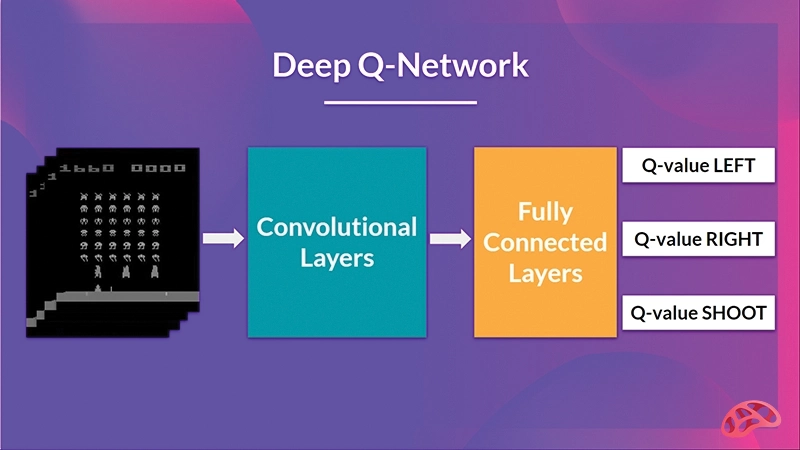
پیش از معرفی DQN، یادگیری تقویتی عمدتاً به محیطهای ساده و کوچک محدود بود. DeepMind نشان داد که میتوان با استفاده از DQN، تنها با دریافت پیکسلهای خام تصویر، بازیهای Atari را در سطحی فراتر از انسان انجام داد؛ آن هم بدون هیچ دانش قبلی از قوانین بازی.
این موفقیت چند پیام مهم داشت:
• یادگیری تقویتی میتواند در محیطهای واقعی و پیچیده مقیاسپذیر باشد.
• شبکههای عصبی عمیق قادرند نمایش مناسبی از حالتها یاد بگیرند.
• یادگیری مبتنی بر تجربه میتواند جایگزین قوانین صریح شود.
Q-Learning؛ پایه نظری DQN
برای درک الگوریتم Deep Q-Network، ابتدا باید با Q-Learning آشنا شد. Q-Learning یک الگوریتم یادگیری تقویتی بدون مدل (Model-Free) است که هدف آن یادگیری تابع Q(s, a) میباشد. این تابع نشان میدهد اگر عامل در حالت s عمل a را انتخاب کند، چه میزان پاداش مورد انتظار در بلندمدت دریافت خواهد کرد. یادگیری در Q-Learning بر اساس تعامل مستقیم عامل با محیط انجام میشود. عامل پس از انجام هر عمل، یک پاداش دریافت کرده و به حالت جدیدی منتقل میشود. سپس مقدار Q مربوط به آن حالت و عمل با استفاده از رابطه زیر بهروزرسانی میگردد:
Q(s,a) ← Q(s,a) + α [ r + γ max Q(s',a') − Q(s,a) ]
در این فرمول، نرخ یادگیری α میزان تأثیر اطلاعات جدید را مشخص میکند و ضریب تنزیل γ اهمیت پاداشهای آینده را نشان میدهد. عبارت max Q(s',a') نیز بهترین ارزش ممکن در حالت بعدی را در نظر میگیرد. با وجود سادگی و قدرت مفهومی، Q-Learning کلاسیک با یک مشکل اساسی مواجه است: این الگوریتم برای ذخیره مقادیر Q به یک جدول وابسته است. در محیطهای بزرگ یا پیچیده، تعداد حالتها بهقدری زیاد میشود که نگهداری و بهروزرسانی این جدول عملاً غیرممکن خواهد بود. همین محدودیت باعث شد ایده استفاده از شبکههای عصبی برای تقریب تابع Q مطرح شود؛ ایدهای که مستقیماً به شکلگیری الگوریتم Deep Q-Network (DQN) انجامید.
ایده اصلی Deep Q-Network
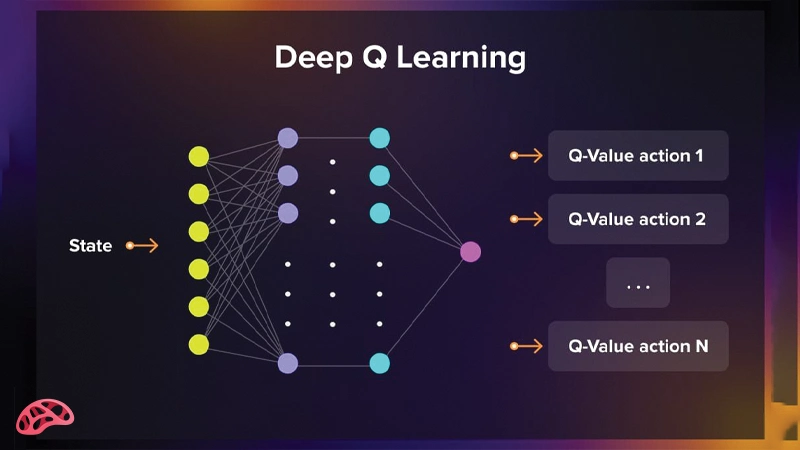
ایده کلیدی الگوریتم Deep Q-Network (DQN) بسیار ساده اما در عین حال انقلابی است. در این روش، بهجای ذخیره مقادیر Q در یک جدول بزرگ و غیرقابلمدیریت، از یک شبکه عصبی عمیق برای تقریب تابع Q(s, a) استفاده میشود. این رویکرد امکان استفاده از Q-Learning را در محیطهایی با فضای حالت بسیار بزرگ یا پیچیده فراهم میکند.
شبکه عصبی در DQN بهگونهای طراحی میشود که:
• ورودی آن، نمایش حالت محیط است؛ این ورودی میتواند دادههای عددی، ویژگیهای استخراجشده یا حتی تصویر خام یک بازی باشد.
• خروجی شبکه، مقادیر Q مربوط به تمام اعمال ممکن در آن حالت است.
به این ترتیب، شبکه عصبی نقش تابع Q را بر عهده میگیرد و بهجای مراجعه به یک جدول، مستقیماً ارزش هر عمل را پیشبینی میکند. عامل سپس با مقایسه این مقادیر، عملی را انتخاب میکند که بیشترین پاداش مورد انتظار را داشته باشد. با تکرار تعامل با محیط و بهروزرسانی وزنهای شبکه، DQN بهتدریج یاد میگیرد که در هر وضعیت، کدام تصمیم بهترین انتخاب است و چگونه سیاست بهینه را بدون نیاز به قوانین از پیش تعریفشده کشف کند.
معماری کلی Deep Q-Network
معماری الگوریتم Deep Q-Network (DQN) از چند بخش اصلی تشکیل شده است که هرکدام نقش مشخصی در بهبود یادگیری و افزایش پایداری مدل دارند. این اجزا بهصورت هماهنگ عمل میکنند تا محدودیتهای Q-Learning کلاسیک را برطرف کنند.
1. شبکه عصبی عمیق (Deep Neural Network)
این شبکه بهعنوان تقریبزن تابع Q عمل میکند و بهجای جدول Q، مقادیر Q(s, a) را تخمین میزند. ورودی شبکه، حالت فعلی محیط است و خروجی آن، مقدار Q برای تمام اعمال ممکن میباشد. ساختار شبکه بسته به نوع داده میتواند کاملاً متصل یا کانولوشنی باشد.
2. حافظه بازپخش تجربه (Experience Replay)
در این بخش، تجربههای عامل شامل حالت، عمل، پاداش و حالت بعدی ذخیره میشوند. نمونهگیری تصادفی از این حافظه باعث کاهش همبستگی دادهها، استفاده بهتر از تجربههای گذشته و افزایش پایداری فرآیند آموزش میشود.
3. شبکه هدف (Target Network)
شبکه هدف نسخهای جداگانه از شبکه اصلی است که برای محاسبه مقادیر هدف استفاده میشود. این شبکه با فاصله زمانی مشخص بهروزرسانی میشود تا از نوسانات شدید و ناپایداری در یادگیری جلوگیری کند.
4. سیاست اکتشاف و بهرهبرداری (Exploration vs Exploitation)
این سیاست تعیین میکند عامل چه زمانی اعمال تصادفی برای کشف محیط انجام دهد و چه زمانی از دانش آموختهشده برای انتخاب بهترین عمل استفاده کند. رایجترین روش در DQN، سیاست ε-greedy است که بهمرور زمان میزان اکتشاف را کاهش میدهد.
Experience Replay؛ چرا حافظه تجربه حیاتی است؟
یکی از چالشهای اصلی در آموزش شبکههای عصبی در یادگیری تقویتی، همبستگی شدید دادههای متوالی است. تجربههایی که عامل پشتسرهم از محیط دریافت میکند معمولاً بسیار شبیه به هم هستند و آموزش مستقیم شبکه روی این دادهها میتواند باعث نوسان، همگرایی ضعیف یا حتی واگرایی فرآیند یادگیری شود.
Experience Replay راهکاری مؤثر برای حل این مشکل است. در این روش، عامل هر تجربه را بهصورت یک چهارتایی شامل (state, action, reward, next_state) در یک حافظه ذخیره میکند. در زمان آموزش، بهجای استفاده از آخرین تجربهها، نمونهها بهصورت تصادفی از این حافظه انتخاب میشوند و شبکه عصبی بر اساس آنها بهروزرسانی میشود. این کار باعث میشود دادههای آموزشی مستقلتر و متنوعتر باشند.
مزایای اصلی Experience Replay عبارتاند از:
• کاهش همبستگی دادهها
نمونهگیری تصادفی باعث میشود شبکه بهجای یادگیری الگوهای کوتاهمدت، روابط کلی و پایدار میان حالتها و اعمال را بیاموزد.
• استفاده بهتر از تجربههای گذشته
هر تجربه میتواند چندین بار در فرآیند آموزش استفاده شود، بدون آنکه عامل مجبور باشد دوباره همان وضعیت را تجربه کند.
• افزایش پایداری یادگیری
ترکیب دادههای قدیمی و جدید باعث میشود بهروزرسانی وزنهای شبکه نرمتر انجام شود و نوسانات شدید کاهش یابد.
بهطور کلی، Experience Replay یکی از مهمترین دلایل موفقیت DQN است و بدون آن، آموزش شبکه عصبی در محیطهای پویا و پیچیده عملاً ناپایدار خواهد بود.
Target Network؛ تثبیت فرآیند آموزش
یکی از نوآوریهای کلیدی در الگوریتم Deep Q-Network (DQN) استفاده از شبکه هدف (Target Network) است؛ روشی که بهطور مستقیم برای کاهش ناپایداری در فرآیند آموزش طراحی شده است. در DQN، استفاده از تنها یک شبکه برای پیشبینی و بهروزرسانی مقادیر Q میتواند باعث نوسانات شدید و واگرایی شود.
در این معماری، دو شبکه عصبی مجزا وجود دارد:
• شبکه اصلی (Online Network)
این شبکه مسئول یادگیری و بهروزرسانی مداوم مقادیر Q است و در هر مرحله از آموزش، وزنهای آن تغییر میکنند.
• شبکه هدف (Target Network)
این شبکه برای محاسبه مقادیر هدف در فرآیند یادگیری استفاده میشود و وزنهای آن بهصورت مستقیم آموزش داده نمیشوند.
شبکه هدف در بازههای زمانی مشخص، وزنهای شبکه اصلی را کپی میکند. ثابت ماندن نسبی این شبکه باعث میشود مقدار هدف در فرمول Q-Learning بهطور ناگهانی تغییر نکند و فرآیند بهروزرسانی شبکه اصلی پایدارتر انجام شود. این تفکیک نقشها، یکی از عوامل اصلی موفقیت DQN در محیطهای پیچیده و پویاست و نقش مهمی در جلوگیری از نوسانات شدید و ناپایداری یادگیری ایفا میکند.
سیاست اکتشاف و بهرهبرداری در DQN
یکی از چالشهای اصلی در یادگیری تقویتی، تعادل بین اکتشاف (Exploration) و بهرهبرداری (Exploitation) است. عامل باید همواره بین امتحان کردن اعمال جدید برای کشف محیط و استفاده از دانش فعلی خود برای انتخاب بهترین عمل، تصمیم بگیرد.
در DQN معمولاً از سیاست ε-greedy استفاده میشود:
• اکتشاف (Exploration): با احتمال ε، عامل یک عمل تصادفی انتخاب میکند تا محیط را بهتر بشناسد و فرصتهای ناشناخته را کشف کند.
• بهرهبرداری (Exploitation): با احتمال 1−ε، عامل بهترین عمل شناختهشده را انتخاب میکند تا پاداش تجمعی را بیشینه کند.
مقدار ε معمولاً در ابتدای آموزش بزرگ است تا عامل آزادی عمل بیشتری برای اکتشاف داشته باشد. به مرور زمان، این مقدار کاهش مییابد تا عامل به تدریج به سیاست بهینه پایبند شود و از اعمال تصادفی کمتر استفاده کند. این سیاست ساده اما مؤثر، به DQN اجازه میدهد همزمان از یادگیری تجارب گذشته بهرهمند شود و هم محیطهای جدید و ناشناخته را کاوش کند، که کلید عملکرد موفق در مسائل پیچیده و پویاست.
جدول مقایسه Q-Learning کلاسیک و DQN
برای درک بهتر جهش مفهومی Deep Q-Network، مقایسه آن با Q-Learning کلاسیک بسیار مفید است. Q-Learning سنتی بر پایه یک جدول Q عمل میکند که در آن برای هر جفت حالت–عمل یک مقدار ذخیره میشود. این رویکرد تنها در محیطهای کوچک و گسسته قابل استفاده است و با افزایش تعداد حالات، بهسرعت غیرعملی میشود. در مقابل، DQN با جایگزینکردن جدول Q با یک شبکه عصبی عمیق، امکان یادگیری در محیطهای بزرگ، پیچیده و حتی با ورودیهایی مانند تصویر را فراهم میکند. جدول مقایسه زیر بهخوبی نشان میدهد که چرا DQN نقطه عطفی در یادگیری تقویتی محسوب میشود و چگونه محدودیتهای Q-Learning کلاسیک را برطرف کرده است.
| ویژگی | Q-Learning کلاسیک | Deep Q-Network |
|---|---|---|
| نمایش تابع Q | جدول | شبکه عصبی عمیق |
| مقیاسپذیری | بسیار محدود | بسیار بالا |
| مناسب محیطهای پیچیده | خیر | بله |
| نیاز به حافظه زیاد | بله | خیر |
| پایداری آموزش | متوسط | بالا (با Replay و Target Network) |
کاربردهای واقعی Deep Q-Network
الگوریتم Deep Q-Network (DQN) تنها یک الگوریتم آزمایشگاهی نیست؛ بلکه در مسائل واقعی و پیچیده نیز کاربردهای گستردهای دارد. ترکیب یادگیری تقویتی و شبکههای عصبی عمیق، امکان تصمیمگیری هوشمند و خودآموزی در محیطهای پویا و بزرگ را فراهم میکند.
برخی از مهمترین کاربردهای DQN عبارتاند از:
• بازیهای کامپیوتری
شامل بازیهای Atari، شطرنج ساده و سایر بازیهای استراتژیک که عامل با مشاهده تصویر یا وضعیت بازی، بهترین عمل را انتخاب میکند و حتی عملکردی فراتر از انسان ارائه میدهد.
• رباتیک
استفاده در کنترل بازوهای رباتیک، ناوبری خودکار و تعامل با محیطهای فیزیکی، بهگونهای که ربات بتواند بدون دستور صریح، مسیر بهینه و حرکات مناسب را یاد بگیرد.
• خودروهای خودران
تصمیمگیری در شرایط پیچیده و پویا مانند تغییر مسیر، اجتناب از موانع و مدیریت سرعت، با استفاده از تجربیات گذشته و پیشبینی نتایج اعمال مختلف.
• سیستمهای توصیهگر پویا
ارائه پیشنهادات شخصیسازیشده در زمان واقعی بر اساس رفتار کاربر و تغییرات محیط، با هدف بهینهسازی تجربه و افزایش تعامل.
• مدیریت منابع و انرژی
تخصیص بهینه منابع در شبکهها، مدیریت مصرف انرژی و تصمیمگیری در شرایط تغییرپذیر، بدون نیاز به برنامهریزی دستی.
• معاملات الگوریتمی و مالی
اتخاذ تصمیمهای هوشمند برای خرید و فروش سهام، پیشبینی بازار و بهینهسازی پرتفوی با یادگیری از دادههای گذشته و شرایط محیط.
محدودیتها و چالشهای DQN
با وجود قدرت و موفقیتهای چشمگیر، الگوریتم Deep Q-Network (DQN) بدون نقص نیست و با چالشهای مشخصی مواجه است. شناخت این محدودیتها برای بهبود الگوریتم و طراحی نسخههای پیشرفته ضروری است.
• نیاز به داده و زمان آموزش زیاد
DQN برای یادگیری سیاست بهینه به حجم بالایی از تجربه و تعامل با محیط نیاز دارد. آموزش شبکههای عصبی عمیق همچنین زمانبر است و نیازمند سختافزار قدرتمند میباشد.
• ناپایداری در محیطهای بسیار پیچیده
در محیطهایی با تعداد زیاد حالت و اعمال یا با تغییرات غیرقابل پیشبینی، فرآیند یادگیری ممکن است ناپایدار باشد و شبکه نتواند به همگرایی کامل برسد.
• عملکرد ضعیف در فضاهای پیوسته اعمال
DQN برای مسائل با فضای اعمال گسسته طراحی شده است. در محیطهایی که اعمال پیوسته هستند، تخمین Q-Valueها دشوار شده و الگوریتم عملکرد مناسبی ندارد.
• حساسیت به هایپرپارامترها
پارامترهایی مانند نرخ یادگیری، ε در سیاست ε-greedy و اندازه حافظه بازپخش تجربه تاثیر زیادی بر کیفیت یادگیری دارند. تنظیم نادرست این پارامترها میتواند باعث کاهش کارایی یا واگرایی الگوریتم شود. این محدودیتها باعث شدهاند پژوهشگران نسخههای پیشرفتهتر DQN را توسعه دهند که برخی از مشکلات یادشده را برطرف میکنند و عملکرد پایدارتری ارائه میدهند.

نسخههای توسعهیافته DQN
با وجود قدرت بالای DQN، محدودیتها و چالشهای آن باعث شد پژوهشگران نسخههای پیشرفتهای از این الگوریتم را توسعه دهند تا عملکرد آن پایدارتر و کارآمدتر شود. این نسخهها هر کدام با هدف رفع یک یا چند مشکل اصلی طراحی شدهاند.
• Double DQN
در نسخه اصلی DQN، مقدار Q اغلب بیشبرآورد میشود، بهویژه در محیطهای با نوسان بالا. Double DQN با جدا کردن انتخاب عمل و ارزیابی مقدار Q، بیشبرآوردها را کاهش میدهد و یادگیری واقعیتری ارائه میکند.
• Dueling DQN
در این نسخه، شبکه عصبی به دو شاخه تقسیم میشود: یکی برای تخمین ارزش حالت (Value) و دیگری برای مزیت عمل (Advantage). ترکیب این دو شاخه به الگوریتم اجازه میدهد تا بهطور بهینهتری میان ارزش کلی حالت و تاثیر هر عمل تفکیک قائل شود.
• Prioritized Experience Replay
در نسخه کلاسیک DQN، نمونهها از حافظه بازپخش بهصورت تصادفی انتخاب میشوند. این نسخه با اولویتبندی نمونهها، تجربههایی که بیشترین تأثیر بر یادگیری دارند را با احتمال بالاتر انتخاب میکند و سرعت و کیفیت آموزش را افزایش میدهد.
• Rainbow DQN
Rainbow DQN ترکیبی از چندین بهبود مهم DQN شامل Double DQN، Dueling DQN، Prioritized Replay و دیگر تکنیکها است. این نسخه عملکرد بسیار بهینهتر و پایدارتر در محیطهای پیچیده ارائه میدهد و یکی از پیشرفتهترین نسخههای DQN محسوب میشود.
آینده DQN در هوش مصنوعی
الگوریتم Deep Q-Network (DQN) نقش بنیادی در توسعه یادگیری تقویتی مدرن ایفا کرده است و هنوز هم بهعنوان پایهای برای بسیاری از الگوریتمهای پیشرفته مورد استفاده قرار میگیرد. درک دقیق DQN برای پژوهشگران و توسعهدهندگان هوش مصنوعی اهمیت ویژهای دارد، چرا که مفاهیم کلیدی آن، مانند شبکه عصبی تقریبزن تابع Q، حافظه بازپخش تجربه و سیاست اکتشاف-بهرهبرداری، در بسیاری از الگوریتمهای نوین نیز بهکار گرفته میشوند.
با وجود رشد و محبوبیت الگوریتمهایی مانند PPO (Proximal Policy Optimization) و SAC (Soft Actor-Critic) در مسائل با فضای حالت و اعمال پیوسته، DQN همچنان در محیطهای گسسته و آموزشی کاربرد گسترده دارد. این الگوریتم در زمینههای آموزشی، بازیها، رباتیک و مسائل تصمیمگیری گسسته بهعنوان یک استاندارد اولیه مورد ارزیابی قرار میگیرد و برای مقایسه و توسعه الگوریتمهای جدید، مرجع قابل اعتمادی محسوب میشود.
در آینده، احتمالاً شاهد ترکیب مفاهیم DQN با الگوریتمهای پیشرفتهتر و یادگیری عمیقتر خواهیم بود تا عملکرد در محیطهای پیچیدهتر و مقیاسپذیری بالاتر افزایش یابد. بهطور خلاصه، DQN همچنان یک سنگ بنای ضروری در یادگیری تقویتی است و یادگیری اصول و مکانیزمهای آن، مسیر توسعه سیستمهای هوشمندتر و خودآموزتر را هموار میکند.
نتیجه گیری:
Deep Q-Network نقطه اتصال یادگیری تقویتی و یادگیری عمیق است. این الگوریتم نشان داد که ماشینها میتوانند تنها با تجربه، بدون قوانین از پیش تعریفشده، به سطحی از تصمیمگیری هوشمند برسند که پیشتر غیرممکن به نظر میرسید. DQN نه پایان راه، بلکه آغاز عصری جدید در هوش مصنوعی بود؛ عصری که در آن تجربه، یادگیری و تطبیق، کلید هوشمندی ماشینهاست.
منبع مقاله:



پاسخ :