
 شاهین آقامعلی
شاهین آقامعلی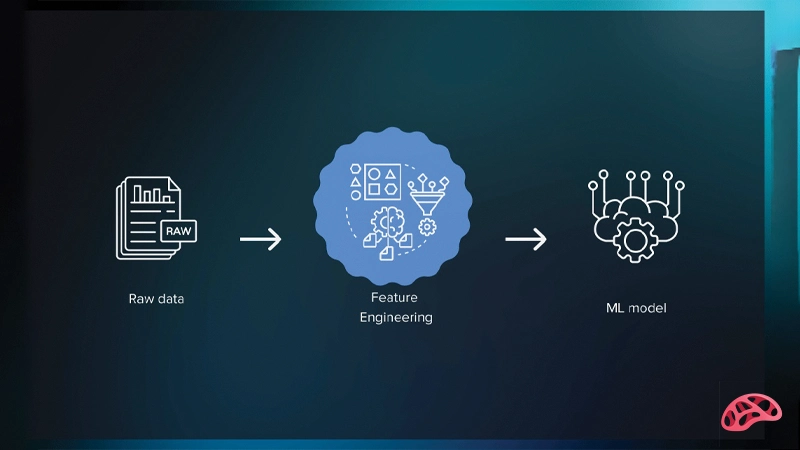
یادگیری ماشین از زیرشاخه های هوش مصنوعی بدون داده بیمعناست، اما نکتهای که بسیاری از افراد تازهکار و حتی برخی متخصصان نادیده میگیرند این است که داده خام بهتنهایی تضمینکننده موفقیت یک مدل نیست. آنچه اغلب تفاوت میان یک مدل ضعیف و یک مدل قدرتمند را رقم میزند، نحوه آمادهسازی و نمایش دادهها برای الگوریتم است. اینجاست که مفهوم Feature Engineering یا مهندسی ویژگیها نقش کلیدی پیدا میکند.
Feature Engineering فرآیندی است که طی آن دادههای خام به ویژگیهایی معنادار، قابل فهم و قابل استفاده برای مدلهای یادگیری ماشین تبدیل میشوند. بسیاری از برندگان مسابقات دادهکاوی و پروژههای موفق صنعتی اعتراف میکنند که بیش از ۶۰٪ زمان پروژه صرف مهندسی ویژگیها میشود، نه انتخاب الگوریتم. در این مقاله بهصورت جامع بررسی میکنیم که Feature Engineering چیست، چرا حیاتی است و چگونه میتواند عملکرد مدلهای یادگیری ماشین را متحول کند. در ادامه با آرتیجنس همراه باشید.
Feature Engineering چیست و چرا اهمیت دارد؟
Feature Engineering در یادگیری ماشین به مجموعهای از تکنیکها و تصمیمها گفته میشود که با هدف استخراج، ساخت، تبدیل یا انتخاب ویژگیها از دادههای خام انجام میگیرد تا مدل یادگیری ماشین بتواند الگوها را بهتر یاد بگیرد. الگوریتمها بهتنهایی هوشمند نیستند؛ آنها فقط الگوهایی را که در دادهها قابل مشاهده است یاد میگیرند. اگر این الگوها بهدرستی در قالب ویژگیها نمایش داده نشوند، حتی پیچیدهترین مدلها نیز شکست میخورند.
اهمیت Feature Engineering از آنجا ناشی میشود که بسیاری از دادههای دنیای واقعی، نویزی، ناقص و غیرساختیافته هستند. مهندسی ویژگیها کمک میکند اطلاعات پنهان در دادهها آشکار شود، روابط غیرخطی بهتر دیده شوند و مدل با سرعت و دقت بیشتری آموزش ببیند. در بسیاری از موارد، یک مدل ساده با Feature Engineering خوب، عملکردی بهتر از یک مدل پیچیده بدون آن دارد.
تفاوت Feature Engineering با Feature Selection و Feature Extraction
قبل از ورود عمیقتر، لازم است تفاوت میان مفاهیم نزدیک به Feature Engineering روشن شود. این حوزه شامل چند زیرمفهوم مهم است که هرکدام نقش متفاوتی در بهبود دادهها دارند.
Feature Selection (انتخاب ویژگیها)
Feature Selection فرآیندی است که طی آن ویژگیهای غیرضروری یا کماهمیت حذف میشوند. هدف این کار کاهش پیچیدگی مدل، جلوگیری از Overfitting و افزایش سرعت آموزش است. در این روش، ویژگی جدیدی ساخته نمیشود، بلکه از میان ویژگیهای موجود بهترینها انتخاب میشوند.
Feature Extraction (استخراج ویژگیها)
در Feature Extraction، دادهها به فضای جدیدی نگاشت میشوند تا اطلاعات مهمتر فشرده و برجسته شوند. روشهایی مانند PCA نمونهای از این رویکرد هستند که ویژگیهای جدیدی بر اساس ترکیب ویژگیهای قبلی تولید میکنند.
| مفهوم | هدف اصلی | ایجاد ویژگی جدید | مثال |
|---|---|---|---|
| Feature Engineering | بهبود نمایش داده | بله | ساخت ویژگی «سن از تاریخ تولد» |
| Feature Selection | کاهش ویژگیها | خیر | حذف ستونهای کماهمیت |
| Feature Extraction | فشردهسازی اطلاعات | بله | PCA |
چرا الگوریتمهای یادگیری ماشین به Feature Engineering نیاز دارند؟
الگوریتمهای یادگیری ماشین بر اساس فرضیات مشخصی درباره دادهها طراحی شدهاند و نمیتوانند روابط پیچیده دنیای واقعی را بهصورت مستقیم از دادههای خام درک کنند. برای مثال، رگرسیون خطی فرض میکند که میان ویژگیها و خروجی رابطهای خطی وجود دارد، در حالی که در بسیاری از مسائل واقعی این رابطه بهطور واضح در داده خام دیده نمیشود و در نتیجه مدل دچار خطا یا کاهش دقت میشود.
Feature Engineering این امکان را فراهم میکند که روابط غیرخطی، پنهان یا وابسته به زمینه مسئله به شکلی مناسب برای الگوریتم نمایش داده شوند. با تبدیل یا ترکیب ویژگیها، مدل میتواند الگوهایی را یاد بگیرد که در حالت اولیه دادهها قابل تشخیص نیستند. برای نمونه، تبدیل یک متغیر زمانی ساده به ویژگیهایی مانند «روز هفته»، «ماه» یا «ساعت اوج مصرف» باعث میشود الگوهای رفتاری و چرخهای که در داده وجود دارند، برای مدل قابل فهم شوند و عملکرد آن بهبود پیدا کند.
مراحل اصلی Feature Engineering در یک پروژه ML
Feature Engineering یک فرآیند خطی و یکباره نیست، بلکه چرخهای تکرارشونده است که در طول توسعه مدل بارها بازبینی میشود. این فرآیند معمولاً با شناخت دقیق مسئله و دادهها آغاز میشود و پس از ارزیابی عملکرد مدل، دوباره اصلاح و بهبود پیدا میکند. درک صحیح این مراحل کمک میکند ویژگیهایی ساخته شوند که واقعاً به بهبود عملکرد مدل منجر شوند، نه اینکه فقط پیچیدگی آن را افزایش دهند.
درک مسئله و دادهها
اولین و مهمترین گام در Feature Engineering، شناخت عمیق مسئله و ماهیت دادههاست. بدون درک دامنه مسئله (Domain Knowledge)، مهندسی ویژگیها بیشتر به آزمون و خطا شباهت خواهد داشت. تحلیل معنای هر ستون، منبع تولید داده، بازه مقادیر و محدودیتهای موجود باعث میشود ویژگیهایی ساخته شوند که با منطق مسئله همخوانی داشته باشند و اطلاعات مفیدی در اختیار مدل قرار دهند.
پاکسازی و آمادهسازی دادهها
پس از شناخت دادهها، مرحله پاکسازی و آمادهسازی آغاز میشود. در این مرحله دادههای ناقص، مقادیر گمشده، نویزها و دادههای پرت شناسایی و مدیریت میشوند. این کار اهمیت زیادی دارد، زیرا کیفیت Feature Engineering مستقیماً به کیفیت داده ورودی وابسته است. ویژگیهایی که از دادههای آلوده ساخته میشوند، میتوانند الگوهای اشتباه به مدل القا کنند و دقت پیشبینی را کاهش دهند.
تکنیکهای رایج Feature Engineering
Feature Engineering شامل مجموعهای گسترده از تکنیکهاست که بسته به نوع دادهها، هدف مسئله و الگوریتم مورد استفاده متفاوت هستند. انتخاب تکنیک مناسب میتواند تأثیر مستقیمی بر دقت، پایداری و سرعت یادگیری مدل داشته باشد. در عمل، ترکیب چند تکنیک ساده اما درست، اغلب نتیجهای بهتر از استفاده افراطی از روشهای پیچیده ایجاد میکند.
تبدیل ویژگیهای عددی
ویژگیهای عددی معمولاً نیاز به پیشپردازش دارند تا برای الگوریتم قابل استفادهتر شوند. نرمالسازی و استانداردسازی باعث میشود مقادیر ویژگیها در یک بازه یا توزیع مشخص قرار بگیرند و از غالب شدن یک متغیر بر سایر متغیرها جلوگیری شود. همچنین در برخی مسائل، استفاده از تبدیلهای ریاضی مانند لگاریتم یا توان میتواند توزیع داده را متعادلتر کند و روابط غیرخطی را بهتر به مدل منتقل کند. این اقدامات بهویژه برای الگوریتمهایی مانند KNN، SVM و شبکههای عصبی که به مقیاس داده حساساند، نقش حیاتی دارند.
مهندسی ویژگیهای دستهای (Categorical)
ویژگیهای دستهای بهصورت مستقیم برای اغلب الگوریتمهای یادگیری ماشین قابل استفاده نیستند و باید به شکل عددی تبدیل شوند. روشهایی مانند One-Hot Encoding برای دادههای با تعداد دسته کم مناسباند، در حالی که Label Encoding یا Target Encoding در دادههای با دستههای زیاد کاربرد بیشتری دارند. انتخاب نادرست روش تبدیل میتواند منجر به افزایش بیش از حد ابعاد داده یا نشت اطلاعات شود، بنابراین شناخت ساختار داده و نوع مدل در این مرحله اهمیت بالایی دارد.
Feature Engineering در دادههای زمانی (Time Series)
دادههای زمانی یکی از مهمترین و در عین حال چالشبرانگیزترین انواع دادهها در یادگیری ماشین هستند. در این نوع دادهها، ترتیب مشاهدات و وابستگی آنها به زمان نقش حیاتی دارد و نادیده گرفتن این ساختار میتواند باعث شود مدل الگوهای واقعی را از دست بدهد. Feature Engineering در دادههای زمانی کمک میکند اطلاعات نهفته در روندها، فصلها و چرخههای تکرارشونده به شکلی قابل یادگیری برای مدل نمایش داده شوند.
ساخت ویژگیهایی مانند lag features، آمارهای متحرک (rolling statistics) و ویژگیهای مبتنی بر تقویم، به مدل امکان میدهد رفتار گذشته را برای پیشبینی آینده در نظر بگیرد. برای مثال، استفاده از مقادیر قبلی یک متغیر یا میانگین آن در بازههای زمانی مشخص، درک بهتری از نوسانات و تغییرات ایجاد میکند. بدون این نوع ویژگیها، مدل معمولاً تنها به مقادیر لحظهای واکنش نشان میدهد و بهجای یادگیری الگوهای معنادار، نویز موجود در داده را دنبال میکند.
نقش Feature Engineering در جلوگیری از Overfitting و Underfitting
یکی از مهمترین مزایای Feature Engineering، کمک به ایجاد تعادل میان Bias و Variance در مدلهای یادگیری ماشین است. زمانی که ویژگیها بیشازحد زیاد، نویزی یا بیکیفیت باشند، مدل ممکن است جزئیات غیرواقعی دادههای آموزشی را یاد بگیرد و دچار Overfitting شود. در مقابل، زمانی که ویژگیها محدود یا فاقد اطلاعات کافی باشند، مدل قادر به یادگیری الگوهای اصلی نبوده و به Underfitting منجر میشود.
با طراحی ویژگیهای معنادار و هدفمند و در عین حال حذف ویژگیهای زائد یا کماثر، میتوان پیچیدگی مدل را در سطح مناسبی نگه داشت. Feature Engineering صحیح باعث میشود مدل روی اطلاعات مهم تمرکز کند و از یادگیری الگوهای تصادفی یا گمراهکننده پرهیز کند. این تعادل میان سادگی و قدرت بیان، یکی از عوامل کلیدی موفقیت مدلها در پروژههای واقعی یادگیری ماشین به شمار میرود.
Feature Engineering در پروژههای واقعی و صنعتی
در محیطهای واقعی و صنعتی، Feature Engineering اغلب نقشی پررنگتر از انتخاب الگوریتم ایفا میکند. بسیاری از شرکتهای بزرگ فناوری سالهاست که بهجای استفاده از مدلهای بسیار پیچیده، از مدلهای نسبتاً ساده اما با ویژگیهای دقیق و مهندسیشده استفاده میکنند. این رویکرد باعث میشود مدلها پایدارتر، قابل تفسیرتر و سازگارتر با شرایط واقعی کسبوکار باشند.
برای مثال، در سیستمهای پیشنهاددهنده، ویژگیهایی مانند «میانگین تعامل کاربر در ۷ روز گذشته»، «تعداد بازدید اخیر» یا «فاصله زمانی از آخرین خرید» تأثیر مستقیمی بر کیفیت پیشبینی دارند. چنین ویژگیهایی حاصل دانش دامنه و درک رفتار کاربران هستند و معمولاً اطلاعات بسیار ارزشمندتری نسبت به دادههای خام در اختیار مدل قرار میدهند. در عمل، همین ویژگیهای هدفمند هستند که تفاوت میان یک مدل آزمایشی و یک سیستم موفق در مقیاس صنعتی را رقم میزنند.

اشتباهات رایج در Feature Engineering
یکی از رایجترین اشتباهات در Feature Engineering، ساخت ویژگیهای زیاد بدون بررسی و ارزیابی تأثیر آنها بر عملکرد مدل است. اضافه کردن ویژگیهای بیاثر نه تنها به بهبود دقت کمک نمیکند، بلکه باعث افزایش پیچیدگی مدل، طولانی شدن زمان آموزش و حتی کاهش قابلیت تعمیم آن میشود. بنابراین پیش از افزودن هر ویژگی جدید، لازم است اثر آن بهطور دقیق سنجیده شود.
اشتباه دیگر، نشت اطلاعات یا Data Leakage است که زمانی رخ میدهد که اطلاعات آینده یا غیرمجاز به مدل منتقل شود و باعث نتایج غیرواقعی و گمراهکننده گردد. همچنین استفاده کورکورانه از تکنیکهای آماده بدون درک کامل دادهها میتواند منجر به یادگیری الگوهای اشتباه توسط مدل شود. Feature Engineering موفق، تلفیقی از دانش علمی داده، شناخت دقیق مسئله و درک رفتار دادههاست که تنها با تجربه و تحلیل دقیق بدست میآید.
آینده Feature Engineering در عصر AutoML و Deep Learning
با ظهور ابزارهای AutoML و مدلهای یادگیری عمیق، برخی تصور میکنند که اهمیت Feature Engineering کاهش یافته و مدلها میتوانند بدون دخالت انسان عملکرد قابل قبولی داشته باشند. در حالی که این ابزارها بخش زیادی از مراحل پیشپردازش و انتخاب ویژگی را خودکار کردهاند، اما همچنان کیفیت دادهها و ساختار صحیح ویژگیها نقش حیاتی در عملکرد نهایی مدل ایفا میکند. دادههای خام ناقص یا نامناسب، حتی در پیشرفتهترین مدلها نیز نتایج ضعیف تولید میکنند.
در حوزه Deep Learning، گرچه مدلها قابلیت یادگیری مستقیم از دادههای پیچیده را دارند، اما انتخاب ورودی مناسب، مهندسی ویژگیهای اولیه و پیشپردازش دقیق دادهها همچنان لازم و ضروری است. به عبارتی، Feature Engineering نه تنها از بین نرفته است، بلکه با توجه به پیچیدگی مدلها و افزایش دادههای بزرگ، به فرآیندی هوشمندتر، تخصصیتر و ترکیبی از دانش دامنه و تکنیکهای پیشرفته تبدیل شده است. این روند نشان میدهد که مهندسی ویژگی در آینده یادگیری ماشین، همچنان یک مهارت کلیدی و ارزشمند باقی خواهد ماند.
نتیجه گیری:
Feature Engineering قلب تپنده پروژههای موفق یادگیری ماشین است. بدون ویژگیهای مناسب، بهترین الگوریتمها نیز ناکارآمد خواهند بود. این فرآیند نیازمند ترکیب دانش فنی، درک داده و شناخت مسئله است و اغلب بیشترین تأثیر را بر عملکرد نهایی مدل دارد. اگر هدف شما ساخت مدلهایی دقیق، پایدار و قابل استفاده در دنیای واقعی است، سرمایهگذاری روی Feature Engineering یک ضرورت است، نه یک انتخاب.
منبع مقاله:



پاسخ :