
 شاهین آقامعلی
شاهین آقامعلی
در دنیای هوش مصنوعی و یادگیری ماشینی (Machine Learning)، هیچ چیز به اندازهی تابع هزینه (Loss Function) در تعیین کیفیت و دقت مدل اهمیت ندارد. این تابع، در واقع قطبنمای مدل است که به آن میگوید چقدر از مسیر درست دور شده و چگونه باید خودش را اصلاح کند. هر بار که مدل پیشبینی انجام میدهد، تابع هزینه میزان خطا را محاسبه کرده و با استفاده از الگوریتمهای بهینهسازی مثل گرادیان نزولی (Gradient Descent)، به مدل میفهماند در چه جهتی باید پارامترهایش را تغییر دهد تا عملکرد بهتری داشته باشد. در این مقاله، ابتدا مفهوم تابع هزینه را توضیح میدهیم، سپس انواع آن را برای مسائل مختلف بررسی میکنیم، و در پایان، دربارهی نحوهی انتخاب و تأثیر آن بر عملکرد مدل بحث خواهیم کرد. در ادامه با آرتیجنس همراه باشید.
مفهوم تابع هزینه در یادگیری ماشینی
تابع هزینه، یک معیار ریاضی است که اختلاف بین خروجی واقعی (y_true) و خروجی پیشبینیشده (y_pred) را اندازهگیری میکند. هدف هر مدل، کمینه کردن مقدار تابع هزینه است. هرچه مقدار این تابع کمتر باشد، به معنای خطای کمتر و عملکرد بهتر مدل است. برای مثال، اگر یک مدل بخواهد قیمت خانهها را پیشبینی کند، تابع هزینه میزان فاصله بین قیمت واقعی و قیمت پیشبینیشده را میسنجد. سپس مدل یادگیری ماشین با تکرار فرآیند یادگیری، ضرایب خود را طوری تنظیم میکند که این فاصله کمتر شود.
تفاوت تابع هزینه (Loss Function) و تابع هدف (Cost Function)
در بسیاری از منابع، این دو اصطلاح بهجای هم استفاده میشوند، اما تفاوت ظریفی دارند:
• تابع هزینه (Loss Function): خطا را برای یک نمونهی خاص محاسبه میکند.
• تابع هدف یا تابع هزینه کلی (Cost Function): میانگین خطاهای تمام دادههای آموزشی است.
در عمل، مدلهای یادگیری ماشینی تابع هدف را بهینهسازی میکنند تا میانگین کل خطاها در کل مجموعه داده حداقل شود.
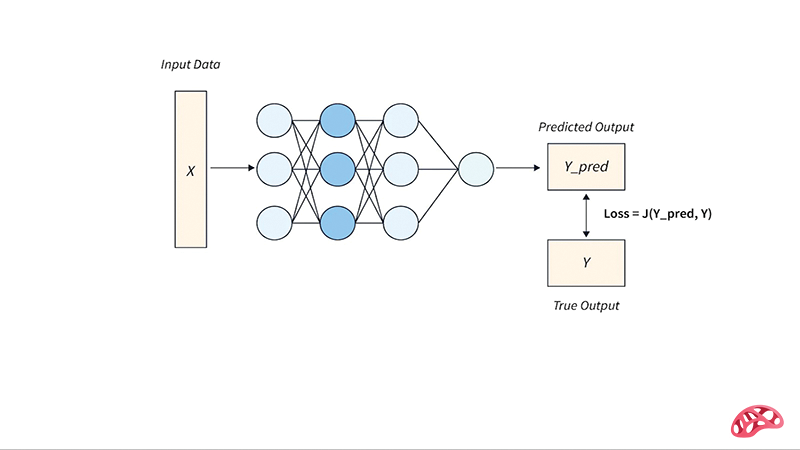
انواع توابع هزینه در یادگیری ماشینی
توابع هزینه بسته به نوع مسئله (رگرسیون، طبقهبندی، یا مدلهای پیچیدهتر مانند شبکههای عصبی) متفاوت هستند. در ادامه، مهمترین دستهها را بررسی میکنیم.
۱. توابع هزینه در مسائل رگرسیون
در مسائل رگرسیون (Regression)، خروجی مدل یک مقدار عددی است (مثلاً قیمت، دما یا وزن). هدف، کاهش اختلاف بین مقدار پیشبینیشده و واقعی است.
۱.۱. Mean Squared Error (MSE)
رایجترین تابع هزینه در رگرسیون است. MSE میانگین مربعات اختلاف بین خروجی واقعی و پیشبینیشده را محاسبه میکند. ویژگی آن این است که خطاهای بزرگتر را شدیدتر جریمه میکند، بنابراین مدل را به دقت بیشتر وادار میکند.
۱.۲. Mean Absolute Error (MAE)
در این روش، میانگین قدر مطلق اختلافها محاسبه میشود. MAE نسبت به خطاهای بزرگ حساسیت کمتری دارد و در دادههایی که دارای نویز هستند عملکرد پایدارتری دارد.
۱.۳. Huber Loss
ترکیبی از MSE و MAE است. برای خطاهای کوچک مثل MSE رفتار میکند و برای خطاهای بزرگ مانند MAE. این تابع در عمل، تعادلی بین دقت بالا و پایداری دارد.
۲. توابع هزینه در مسائل طبقهبندی
در طبقهبندی (Classification)، هدف پیشبینی برچسب درست برای هر نمونه است. اینجا توابع هزینه برای اندازهگیری فاصلهی بین احتمال پیشبینیشده و برچسب واقعی استفاده میشوند.
۲.۱. Binary Cross-Entropy
برای طبقهبندی دوکلاسه (مثلاً بله/خیر) استفاده میشود. این تابع، فاصلهی بین توزیع واقعی و پیشبینیشده را با محاسبهی آنتروپی اندازه میگیرد. هرچه مقدار آن کمتر باشد، مدل در تشخیص درستتر عمل کرده است.
۲.۲. Categorical Cross-Entropy
نسخهی چندکلاسهی Binary Cross-Entropy است. برای مدلهایی مثل شبکههای عصبی در تشخیص تصویر، صدا یا متن کاربرد دارد.
۲.۳. Hinge Loss
تابع هزینهی اصلی در الگوریتم SVM (Support Vector Machine) است. این تابع مدل را طوری آموزش میدهد که مرز تصمیمگیری بین دستهها با بیشترین فاصله ممکن از دادهها باشد.
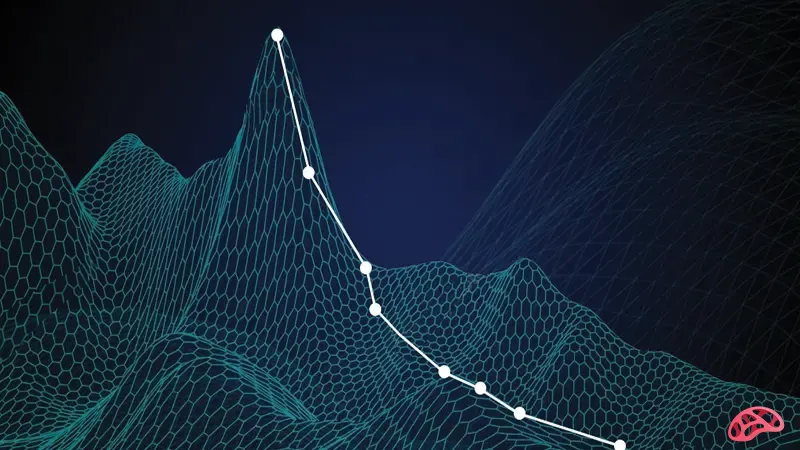
۳. توابع هزینه در شبکههای عصبی و یادگیری عمیق
در شبکههای عصبی (Neural Networks)، انتخابتابع هزینه میتواند تعیینکنندهی مسیر یادگیری مدل باشد.
۳.۱. Kullback-Leibler Divergence
برای مقایسهی دو توزیع احتمالی (مثلاً خروجی شبکه و توزیع واقعی) استفاده میشود. در مدلهای هوش مصنوعی مولد (Generative Models) مثل VAE کاربرد زیادی دارد.
۳.۲. Dice Loss
در کاربردهای بینایی ماشین (Computer Vision)، بهویژه در بخشبندی تصاویر پزشکی، بسیار رایج است. هدف آن حداکثر کردن میزان همپوشانی بین پیکسلهای پیشبینیشده و پیکسلهای واقعی است.
۳.۳. Focal Loss
برای مقابله با مشکل دادههای نامتوازن (Class Imbalance) استفاده میشود. این تابع، نمونههای سختتر را وزن بیشتری میدهد تا مدل تمرکز خود را بر آنها بگذارد.
چگونه تابع هزینه مناسب را انتخاب کنیم؟
انتخاب تابع هزینه مناسب، یکی از حیاتیترین تصمیمها در طراحی مدل است. چند عامل در این انتخاب نقش دارند:
• نوع مسئله: طبقهبندی، رگرسیون یا یادگیری مولد
• ماهیت دادهها: اگر دادهها نویزی هستند، تابعی مقاوم مثل MAE یا Huber Loss بهتر عمل میکند.
• اهداف پروژه: اگر تمرکز بر دقت نهایی است، MSE یا Cross-Entropy گزینههای خوبیاند؛ اگر بر پایداری تأکید دارید، Lossهای ترکیبی کارآمدترند.
• حساسیت به خطا: در برخی کاربردها مثل پزشکی یا مالی، خطاهای بزرگ هزینهبر هستند، بنابراین Loss باید حساستر انتخاب شود.

تأثیر تابع هزینه بر عملکرد مدل
تابع هزینه نهتنها مسیر آموزش مدل را تعیین میکند بلکه جهت بهروزرسانی وزنها و سرعت یادگیری را هم مشخص میکند. اگر تابع هزینه اشتباه انتخاب شود، حتی بهترین دادهها و الگوریتمها هم ممکن است نتیجهی مطلوب ندهند. برای مثال:
• انتخاب MSE در دادههای دارای نویز باعث نوسان مدل میشود.
• انتخاب Cross-Entropy در دادههای چندکلاسه، دقت مدل را در مرز تصمیمگیری بهبود میدهد.
• در شبکههای عمیق، Loss مناسب میتواند از گرادیان ناپدیدشونده (Vanishing Gradient) جلوگیری کند.
در واقع، تابع هزینه همان قلب تپندهی فرآیند یادگیری است. بدون آن، مدل نمیداند چه چیزی را باید یاد بگیرد.
آیندهی توابع هزینه در یادگیری ماشینی
در سالهای اخیر، پژوهشگران به سمت توابع هزینه پویا و تطبیقی (Adaptive Loss Functions) حرکت کردهاند. در این روشها، تابع هزینه در طول آموزش تغییر میکند تا خود را با نوع داده و سطح یادگیری مدل هماهنگ سازد. همچنین، با ظهور مدلهای مولد (Generative AI) مانند GPT و Stable Diffusion، توابع هزینه پیچیدهتری مثل Contrastive Loss و Perceptual Loss وارد عرصه شدهاند که کیفیت خروجیهای زبانی و تصویری را بهطرز چشمگیری بهبود دادهاند.
نتیجه گیری
تابع هزینه یکی از مهمترین مؤلفههای هر مدل یادگیری ماشینی است. این تابع مسیر یادگیری مدل را هدایت میکند، میزان خطا را میسنجد و به مدل کمک میکند تا به بهترین نسخه از خودش تبدیل شود. در واقع، اگر دادهها سوخت موتور هوش مصنوعی باشند، تابع هزینه نقشهی راه آن است. با انتخاب درست و آگاهانهیتابع هزینه متناسب با نوع داده و هدف پروژه، میتوان عملکرد مدلهای یادگیری ماشینی را به شکل چشمگیری بهبود داد و از فناوری هوش مصنوعی بیشترین بهره را گرفت.
منبع مقاله:



پاسخ :